Seeking Employment
January 07, 2019 at 03:25 PM | categories: Personal, MozillaAfter almost seven and a half years as an employee of Mozilla Corporation, I'm moving on. I have already worked my final day as an employee.
This post is the first time that I've publicly acknowledged my departure. To any Mozillians reading this, I regret that I did not send out a farewell email before I left. But the circumstances of my departure weren't conducive to doing so. I've been drafting a proper farewell blog post. But it has been very challenging to compose. Furthermore, each passing day brings with it new insights into my time at Mozilla and a new wrinkle to integrate into the reflective story I want to tell in that post. I vow to eventually publish a proper goodbye that serves as the bookend to my employment at Mozilla. Until then, just let me say that I'm already missing working with many of you. I've connected with several people since I left and still owe responses or messages to many more. If you want to get in touch, my contact info is in my résumé.
I left Mozilla without new employment lined up. That leads me to the subject line of this post: I'm seeking employment. The remainder of this post is thus tailored to potential employers.
My résumé has been updated. But that two page summary only scratches the surface of my experience and set of skills. The Body of Work page of my website is a more detailed record of the work I've done. But even it is not complete!
Perusing through my posts on this blog will reveal even more about the work I've done and how I go about it. My résumé links to a few posts that I think are great examples of the level of understanding and detail that I'm capable of harnessing.
As far as the kind of work I want to do or the type of company I want to work for, I'm trying to keep an open mind. But I do have some biases.
I prefer established companies to early start-ups for various reasons. Dan Luu's Big companies v. startups is aligned pretty well with my thinking.
One of the reasons I worked for Mozilla was because of my personal alignment with the Mozilla Manifesto. So I gravitate towards employers that share those principles and am somewhat turned off by those that counteract them. But I recognize that the world is complex and that competing perspectives aren't intrinsically evil. In other words, I try to maintain an open mind.
I'm attracted to employers that align their business with improving the well-being of the planet, especially the people on it. The link between the business and well-being can be tenuous: a B2B business for example is presumably selling something that helps people, and that helping is what matters to me. The tighter the link between the business and improving the world will increase my attraction to a employer.
I started my university education as a biomedical engineer because I liked the idea of being at the intersection of technology and medicine. And part of me really wants to return to this space because there are few things more noble than helping a fellow human being in need.
As for the kind of role or technical work I want to do, I could go in any number of directions. I still enjoy doing individual contributor type work and believe I could be an asset to an employer doing that work. But I also crave working on a team, performing technical mentorship, and being a leader of technical components. I enjoy participating in high-level planning as well as implementing the low-level aspects. I recognize that while my individual output can be substantial (I can provide data showing that I was one of the most prolific technical contributors at Mozilla during my time there) I can be more valuable to an employer when I bestow skills and knowledge unto others through teaching, mentorship, setting an example, etc.
I have what I would consider expertise in a few domains that may be attractive to employers.
I was a technical maintainer of Firefox's build system and initiated a transition away from an architecture that had been in place since the Netscape days. I definitely geek out way too much on build systems.
I am a contributor to the Mercurial version control tool. I know way too much about the internals of Mercurial, Git, and other version control tools. I am intimately aware of scaling problems with these tools. Some of the scaling work I did for Mercurial saved Mozilla tens of thousands of dollars in direct operational costs and probably hundreds of thousands of dollars in saved people time due to fewer service disruptions and faster operations.
I have exposure to both client and server side work and the problems encountered within each domain. I've dabbled in lots of technologies, operating systems, and tools. I'm not afraid to learn something new. Although as my experience increases, so does my skepticism of shiny new things (I've been burned by technical fads too many times).
I have a keen fascination with optimization and scaling, whether it be on a technical level or in terms of workflows and human behavior. I like to ask and then what so I'm thinking a few steps out and am prepared for the next problem or consequence of an immediate action.
I seem to have a knack for caring about user experience and interfaces. (Although my own visual design skills aren't the greatest - see my website design for proof.) I'm pretty passionate that tools that people use should be simple and usable. Cognitive dissonance, latency, and distractions are real and as an industry we don't do a great job minimizing these disruptions so focus and productivity can be maximized. I'm not saying I would be a good product manager or UI designer. But it's something I've thought about because not many engineers seem to exhibit the passion for good user experience that I do and that intersection of skills could be valuable.
My favorite time at Mozilla was when I was working on a unified engineering productivity team. The team controlled most of the tools and infrastructure that Firefox developers interacted with in order to do their jobs. I absolutely loved taking a whole-world view of that problem space and identifying the high-level problems - and low-hanging fruit - to improve the overall Firefox development experience. I derived a lot of satisfaction from identifying pain points, equating them to a dollar cost by extrapolating people time wasted due to them, justifying working on them, and finally celebrating - along with the overall engineering team - when improvements were made. I think I would be a tremendous asset to a company working in this space. And if my experience at Mozilla is any indicator, I would more than offset my total employment cost by doing this kind of work.
I've been entertaining the idea of contracting for a while before I resume full-time employment with a single employer. However, I've never contracted before and need to do some homework before I commit to that. (Please leave a comment or email me if you have recommendations on reading material.)
My dream contract gig would likely be to finish the Mercurial wire protocol and storage work I started last year. I would need to type up a formal proposal, but the gist of it is the work I started has the potential to leapfrog Git in terms of both client-side and server-side performance and scalability. Mercurial would be able to open Git repositories on the local filesystem as well as consume them via the Git wire protocol. Transparent Git interoperability would enable Mercurial to be used as a drop-in replacement for Git, which would benefit users who don't have control over the server (such as projects that live on GitHub). Mercurial's new wire protocol is designed with global scalability and distribution in mind. The goal is to enable server operators to deploy scalable VCS servers in a turn-key manner by relying on scalable key-value stores and content distribution networks as much as possible (Mercurial and Git today require servers to perform way too much work and aren't designed with modern distributed systems best practices, which is why scaling them is hard). The new protocol is being designed such that a Mercurial server could expose Git data. It would then be possible to teach a Git client to speak the Mercurial wire protocol, which would result in Mercurial being a more scalable Git server than Git is today. If my vision is achieved, this would make server-side VCS scaling problems go away and would eliminate the religious debate between Git and Mercurial (the answer would be deploy a Mercurial server, allow data to be exposed to Git, and let consumers choose). I conservatively estimate that the benefits to industry would be in the millions of dollars. How I would structure a contract to deliver aspects of this, I'm not sure. But if you are willing to invest six figures towards this bet, let's talk. A good foundation of this work is already implemented in Mercurial and the Mercurial core development team is already on-board with many aspects of the vision, so I'm not spewing vapor.
Another potential contract opportunity would be funding PyOxidizer. I started the project a few months back as a side-project as an excuse to learn Rust while solving a fun problem that I thought needed solving. I was hoping for the project to be useful for Mercurial and Mozilla one day. But if social media activity is any indication, there seems to be somewhat widespread interest in this project. I have no doubt that once complete, companies will be using PyOxidizer to ship products that generate revenue and that PyOxidizer will save them engineering resources. I'd very much like to recapture some of that value into my pockets, if possible. Again, I'm somewhat naive about how to write contracts since I've never contracted, but I imagine deliver a tool that allows me to ship product X as a standalone binary to platforms Y and Z is definitely something that could be structured as a contract.
As for the timeline, I was at Mozilla for what feels like an eternity in Silicon Valley. And Mozilla's way of working is substantially different from many companies. I need some time to decompress and unlearn some Mozilla habits. My future employer will inherit a happier and more productive employee by allowing me to take some much-needed time off.
I'm looking to resume full-time work no sooner than March 1. I'd like to figure out what the next step in my career is by the end of January. Then I can sign some papers, pack up my skiis, and become a ski bum for the month of February: if I don't use this unemployment opportunity to have at least 20 days on the slopes this season and visit some new mountains, I will be very disappointed in myself!
If you want to get in touch, my contact info is in my résumé. I tend not to answer incoming calls from unknown numbers, so email is preferred. But if you leave a voicemail, I'll try to get back to you.
I look forward to working for a great engineering organization in the near future!
Absorbing Commit Changes in Mercurial 4.8
November 05, 2018 at 09:25 AM | categories: Mercurial, MozillaEvery so often a tool you use introduces a feature that is so useful
that you can't imagine how things were before that feature existed.
The recent 4.8 release of the
Mercurial version control tool introduces
such a feature: the hg absorb command.
hg absorb is a mechanism to automatically and intelligently incorporate
uncommitted changes into prior commits. Think of it as hg histedit or
git rebase -i with auto squashing.
Imagine you have a set of changes to prior commits in your working
directory. hg absorb figures out which changes map to which commits
and absorbs each of those changes into the appropriate commit. Using
hg absorb, you can replace cumbersome and often merge conflict ridden
history editing workflows with a single command that often just works.
Read on for more details and examples.
Modern version control workflows often entail having multiple unlanded commits in flight. What this looks like varies heavily by the version control tool, standards and review workflows employed by the specific project/repository, and personal preferences.
A workflow practiced by a lot of projects is to author your commits into a sequence of standalone commits, with each commit representing a discrete, logical unit of work. Each commit is then reviewed/evaluated/tested on its own as part of a larger series. (This workflow is practiced by Firefox, the Git and Mercurial projects, and the Linux Kernel to name a few.)
A common task that arises when working with such a workflow is the need to incorporate changes into an old commit. For example, let's say we have a stack of the following commits:
$ hg show stack
@ 1c114a ansible/hg-web: serve static files as immutable content
o d2cf48 ansible/hg-web: synchronize templates earlier
o c29f28 ansible/hg-web: convert hgrc to a template
o 166549 ansible/hg-web: tell hgweb that static files are in /static/
o d46d6a ansible/hg-web: serve static template files from httpd
o 37fdad testing: only print when in verbose mode
/ (stack base)
o e44c2e (@) testing: install Mercurial 4.8 final
Contained within this stack are 5 commits changing the way that static files are served by hg.mozilla.org (but that's not important).
Let's say I submit this stack of commits for review. The reviewer spots a problem with the second commit (serve static template files from httpd) and wants me to make a change.
How do you go about making that change?
Again, this depends on the exact tool and workflow you are using.
A common workflow is to not rewrite the existing commits at all: you simply create a new fixup commit on top of the stack, leaving the existing commits as-is. e.g.:
$ hg show stack
o deadad fix typo in httpd config
o 1c114a ansible/hg-web: serve static files as immutable content
o d2cf48 ansible/hg-web: synchronize templates earlier
o c29f28 ansible/hg-web: convert hgrc to a template
o 166549 ansible/hg-web: tell hgweb that static files are in /static/
o d46d6a ansible/hg-web: serve static template files from httpd
o 37fdad testing: only print when in verbose mode
/ (stack base)
o e44c2e (@) testing: install Mercurial 4.8 final
When the entire series of commits is incorporated into the repository,
the end state of the files is the same, so all is well. But this strategy
of using fixup commits (while popular - especially with Git-based tooling
like GitHub that puts a larger emphasis on the end state of changes rather
than the individual commits) isn't practiced by all projects.
hg absorb will not help you if this is your workflow.
A popular variation of this fixup commit workflow is to author a new commit then incorporate this commit into a prior commit. This typically involves the following actions:
<save changes to a file>
$ hg commit
<type commit message>
$ hg histedit
<manually choose what actions to perform to what commits>
OR
<save changes to a file>
$ git add <file>
$ git commit
<type commit message>
$ git rebase --interactive
<manually choose what actions to perform to what commits>
Essentially, you produce a new commit. Then you run a history editing command. You then tell that history editing command what to do (e.g. to squash or fold one commit into another), that command performs work and produces a set of rewritten commits.
In simple cases, you may make a simple change to a single file. Things are pretty straightforward. You need to know which two commits to squash together. This is often trivial. Although it can be cumbersome if there are several commits and it isn't clear which one should be receiving the new changes.
In more complex cases, you may make multiple modifications to multiple files. You may even want to squash your fixups into separate commits. And for some code reviews, this complex case can be quite common. It isn't uncommon for me to be incorporating dozens of reviewer-suggested changes across several commits!
These complex use cases are where things can get really complicated for version control tool interactions. Let's say we want to make multiple changes to a file and then incorporate those changes into multiple commits. To keep it simple, let's assume 2 modifications in a single file squashing into 2 commits:
<save changes to file>
$ hg commit --interactive
<select changes to commit>
<type commit message>
$ hg commit
<type commit message>
$ hg histedit
<manually choose what actions to perform to what commits>
OR
<save changes to file>
$ git add <file>
$ git add --interactive
<select changes to stage>
$ git commit
<type commit message>
$ git add <file>
$ git commit
<type commit message>
$ git rebase --interactive
<manually choose which actions to perform to what commits>
We can see that the number of actions required by users has already increased
substantially. Not captured by the number of lines is the effort that must go
into the interactive commands like hg commit --interactive,
git add --interactive, hg histedit, and git rebase --interactive. For
these commands, users must tell the VCS tool exactly what actions to take.
This takes time and requires some cognitive load. This ultimately distracts
the user from the task at hand, which is bad for concentration and productivity.
The user just wants to amend old commits: telling the VCS tool what actions
to take is an obstacle in their way. (A compelling argument can be made that
the work required with these workflows to produce a clean history is too much
effort and it is easier to make the trade-off favoring simpler workflows
versus cleaner history.)
These kinds of squash fixup workflows are what hg absorb is designed to
make easier. When using hg absorb, the above workflow can be reduced to:
<save changes to file>
$ hg absorb
<hit y to accept changes>
OR
<save changes to file>
$ hg absorb --apply-changes
Let's assume the following changes are made in the working directory:
$ hg diff
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -76,7 +76,7 @@ LimitRequestFields 1000
# Serve static files straight from disk.
<Directory /repo/hg/htdocs/static/>
Options FollowSymLinks
- AllowOverride NoneTypo
+ AllowOverride None
Require all granted
</Directory>
@@ -86,7 +86,7 @@ LimitRequestFields 1000
# and URLs are versioned by the v-c-t revision, they are immutable
# and can be served with aggressive caching settings.
<Location /static/>
- Header set Cache-Control "max-age=31536000, immutable, bad"
+ Header set Cache-Control "max-age=31536000, immutable"
</Location>
#LogLevel debug
That is, we have 2 separate uncommitted changes to
ansible/roles/hg-web/templates/vhost.conf.j2.
Here is what happens when we run hg absorb:
$ hg absorb
showing changes for ansible/roles/hg-web/templates/vhost.conf.j2
@@ -78,1 +78,1 @@
d46d6a7 - AllowOverride NoneTypo
d46d6a7 + AllowOverride None
@@ -88,1 +88,1 @@
1c114a3 - Header set Cache-Control "max-age=31536000, immutable, bad"
1c114a3 + Header set Cache-Control "max-age=31536000, immutable"
2 changesets affected
1c114a3 ansible/hg-web: serve static files as immutable content
d46d6a7 ansible/hg-web: serve static template files from httpd
apply changes (yn)?
<press "y">
2 of 2 chunk(s) applied
hg absorb automatically figured out that the 2 separate uncommitted changes
mapped to 2 different changesets (Mercurial's term for commit). It
print a summary of what lines would be changed in what changesets and
prompted me to accept its plan for how to proceed. The human effort involved
is a quick review of the proposed changes and answering a prompt.
At a technical level, hg absorb finds all uncommitted changes and
attempts to map each changed line to an unambiguous prior commit. For
every change that can be mapped cleanly, the uncommitted changes are
absorbed into the appropriate prior commit. Commits impacted by the
operation are rebased automatically. If a change cannot be mapped to an
unambiguous prior commit, it is left uncommitted and users can fall back
to an existing workflow (e.g. using hg histedit).
But wait - there's more!
The automatic rewriting logic of hg absorb is implemented by following
the history of lines. This is fundamentally different from the approach
taken by hg histedit or git rebase, which tend to rely on merge
strategies based on the
3-way merge
to derive a new version of a file given multiple input versions. This
approach combined with the fact that hg absorb skips over changes with
an ambiguous application commit means that hg absorb will never
encounter merge conflicts! Now, you may be thinking if you ignore
lines with ambiguous application targets, the patch would always apply
cleanly using a classical 3-way merge. This statement logically sounds
correct. But it isn't: hg absorb can avoid merge conflicts when the
merging performed by hg histedit or git rebase -i would fail.
The above example attempts to exercise such a use case. Focusing on the initial change:
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -76,7 +76,7 @@ LimitRequestFields 1000
# Serve static files straight from disk.
<Directory /repo/hg/htdocs/static/>
Options FollowSymLinks
- AllowOverride NoneTypo
+ AllowOverride None
Require all granted
</Directory>
This patch needs to be applied against the commit which introduced it. That commit had the following diff:
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -73,6 +73,15 @@ LimitRequestFields 1000
{% endfor %}
</Location>
+ # Serve static files from templates directory straight from disk.
+ <Directory /repo/hg/hg_templates/static/>
+ Options None
+ AllowOverride NoneTypo
+ Require all granted
+ </Directory>
+
+ Alias /static/ /repo/hg/hg_templates/static/
+
#LogLevel debug
LogFormat "%h %v %u %t \"%r\" %>s %b %D \"%{Referer}i\" \"%{User-Agent}i\" \"%{Cookie}i\""
ErrorLog "/var/log/httpd/hg.mozilla.org/error_log"
But after that commit was another commit with the following change:
diff --git a/ansible/roles/hg-web/templates/vhost.conf.j2 b/ansible/roles/hg-web/templates/vhost.conf.j2
--- a/ansible/roles/hg-web/templates/vhost.conf.j2
+++ b/ansible/roles/hg-web/templates/vhost.conf.j2
@@ -73,14 +73,21 @@ LimitRequestFields 1000
{% endfor %}
</Location>
- # Serve static files from templates directory straight from disk.
- <Directory /repo/hg/hg_templates/static/>
- Options None
+ # Serve static files straight from disk.
+ <Directory /repo/hg/htdocs/static/>
+ Options FollowSymLinks
AllowOverride NoneTypo
Require all granted
</Directory>
...
When we use hg histedit or git rebase -i to rewrite this history, the VCS
would first attempt to re-order commits before squashing 2 commits together.
When we attempt to reorder the fixup diff immediately after the commit that
introduces it, there is a good chance your VCS tool would encounter a merge
conflict. Essentially your VCS is thinking you changed this line but the
lines around the change in the final version are different from the lines
in the initial version: I don't know if those other lines matter and therefore
I don't know what the end state should be, so I'm giving up and letting the
user choose for me.
But since hg absorb operates at the line history level, it knows that this
individual line wasn't actually changed (even though the lines around it did),
assumes there is no conflict, and offers to absorb the change. So not only
is hg absorb significantly simpler than today's hg histedit or
git rebase -i workflows in terms of VCS command interactions, but it can
also avoid time-consuming merge conflict resolution as well!
Another feature of hg absorb is that all the rewriting occurs in memory
and the working directory is not touched when running the command. This means
that the operation is fast (working directory updates often account for a lot
of the execution time of hg histedit or git rebase commands). It also means
that tools looking at the last modified time of files (e.g. build systems
like GNU Make) won't rebuild extra (unrelated) files that were touched
as part of updating the working directory to an old commit in order to apply
changes. This makes hg absorb more friendly to edit-compile-test-commit
loops and allows developers to be more productive.
And that's hg absorb in a nutshell.
When I first saw a demo of hg absorb at a Mercurial developer meetup, my
jaw - along with those all over the room - hit the figurative floor. I thought
it was magical and too good to be true. I thought Facebook (the original authors
of the feature) were trolling us with an impossible demo. But it was all real.
And now hg absorb is available in the core Mercurial distribution for anyone
to use.
From my experience, hg absorb just works almost all of the time: I run
the command and it maps all of my uncommitted changes to the appropriate
commit and there's nothing more for me to do! In a word, it is magical.
To use hg absorb, you'll need to activate the absorb extension. Simply
put the following in your hgrc config file:
[extensions]
absorb =
hg absorb is currently an experimental feature. That means there is
no commitment to backwards compatibility and some rough edges are
expected. I also anticipate new features (such as hg absorb --interactive)
will be added before the experimental label is removed. If you encounter
problems or want to leave comments, file a bug,
make noise in #mercurial on Freenode, or
submit a patch.
But don't let the experimental label scare you away from using it:
hg absorb is being used by some large install bases and also by many
of the Mercurial core developers. The experimental label is mainly there
because it is a brand new feature in core Mercurial and the experimental
label is usually affixed to new features.
If you practice workflows that frequently require amending old commits, I
think you'll be shocked at how much easier hg absorb makes these workflows.
I think you'll find it to be a game changer: once you use hg abosrb, you'll
soon wonder how you managed to get work done without it.
Benefits of Clone Offload on Version Control Hosting
July 27, 2018 at 03:48 PM | categories: Mercurial, MozillaBack in 2015, I implemented a feature in Mercurial 3.6 that allows
servers to advertise URLs of pre-generated bundle files. When a
compatible client performs a hg clone against a repository leveraging
this feature, it downloads and applies the bundle from a URL then goes
back to the server and performs the equivalent of an hg pull to obtain
the changes to the repository made after the bundle was generated.
On hg.mozilla.org, we've been using this feature since 2015. We host bundles in Amazon S3 and make them available via the CloudFront CDN. We perform IP filtering on the server so clients connecting from AWS IPs are served S3 URLs corresponding to the closest region / S3 bucket where bundles are hosted. Most Firefox build and test automation is run out of EC2 and automatically clones high-volume repositories from an S3 bucket hosted in the same AWS region. (Doing an intra-region transfer is very fast and clones can run at >50 MB/s.) Everyone else clones from a CDN. See our official docs for more.
I last reported on this feature in October 2015. Since then, Bitbucket also deployed this feature in early 2017.
I was reminded of this clone bundles feature this week when kernel.org posted Best way to do linux clones for your CI and that post was making the rounds in my version control circles. tl;dr git.kernel.org apparently suffers high load due to high clone volume against the Linux Git repository and since Git doesn't have an equivalent feature to clone bundles built in to Git itself, they are asking people to perform equivalent functionality to mitigate server load.
(A clone bundles feature has been discussed on the Git mailing list before. I remember finding old discussions when I was doing research for Mercurial's feature in 2015. I'm sure the topic has come up since.)
Anyway, I thought I'd provide an update on just how valuable the clone bundles feature is to Mozilla. In doing so, I hope maintainers of other version control tools see the obvious benefits and consider adopting the feature sooner.
In a typical week, hg.mozilla.org is currently serving ~135 TB of data. The overwhelming majority of this data is related to the Mercurial wire protocol (i.e. not HTML / JSON served from the web interface). Of that ~135 TB, ~5 TB is served from the CDN, ~126 TB is served from S3, and ~4 TB is served from the Mercurial servers themselves. In other words, we're offloading ~97% of bytes served from the Mercurial servers to S3 and the CDN.
If we assume this offloaded ~131 TB is equally distributed throughout the week, this comes out to ~1,732 Mbps on average. In reality, we do most of our load from California's Sunday evenings to early Friday evenings. And load is typically concentrated in the 12 hours when the sun is over Europe and North America (where most of Mozilla's employees are based). So the typical throughput we are offloading is more than 2 Gbps. And at a lower level, automation tends to perform clones soon after a push is made. So load fluctuates significantly throughout the day, corresponding to when pushes are made.
By volume, most of the data being offloaded is for the mozilla-unified Firefox repository. Without clone bundles and without the special stream clone Mercurial feature (which we also leverage via clone bundles), the servers would be generating and sending ~1,588 MB of zstandard level 3 compressed data for each clone of that repository. Each clone would consume ~280s of CPU time on the server. And at ~195,000 clones per month, that would come out to ~309 TB/mo or ~72 TB/week. In CPU time, that would be ~54.6 million CPU-seconds, or ~21 CPU-months. I will leave it as an exercise to the reader to attach a dollar cost to how much it would take to operate this service without clone bundles. But I will say the total AWS bill for our S3 and CDN hosting for this service is under $50 per month. (It is worth noting that intra-region data transfer from S3 to other AWS services is free. And we are definitely taking advantage of that.)
Despite a significant increase in the size of the Firefox repository and clone volume of it since 2015, our servers are still performing less work (in terms of bytes transferred and CPU seconds consumed) than they were in 2015. The ~97% of bytes and millions of CPU seconds offloaded in any given week have given us a lot of breathing room and have saved Mozilla several thousand dollars in hosting costs. The feature has likely helped us avoid many operational incidents due to high server load. It has made Firefox automation faster and more reliable.
Succinctly, Mercurial's clone bundles feature has successfully and largely effortlessly offloaded a ton of load from the hg.mozilla.org Mercurial servers. Other version control tools should implement this feature because it is a game changer for server operators and results in a better client-side experience (eliminates server-side CPU bottleneck and may eliminate network bottleneck due to a geo-local CDN typically being as fast as your Internet pipe). It's a win-win. And a massive win if you are operating at scale.
Deterministic Firefox Builds
June 20, 2018 at 11:10 AM | categories: MozillaAs of Firefox 60, the build environment for official Firefox Linux builds switched from CentOS to Debian.
As part of the transition, we overhauled how the build environment for Firefox is constructed. We now populate the environment from deterministic package snapshots and are much more stringent about dependencies and operations being deterministic and reproducible. The end result is that the build environment for Firefox is deterministic enough to enable Firefox itself to be built deterministically.
Changing the underlying operating system environment used for builds was a risky change. Differences in the resulting build could result in new bugs or some users not being able to run the official builds. We figured a good way to mitigate that risk was to make the old and new builds as bit-identical as possible. After all, if the environments produce the same bits, then nothing has effectively changed and there should be no new risk for end-users.
Employing the diffoscope tool, we identified areas where Firefox builds weren't deterministic in the same environment and where there was variance across build environments. We iterated on differences and changed systems so variance would no longer occur. By the end of the process, we had bit-identical Firefox builds across environments.
So, as of Firefox 60, Firefox builds on Linux are deterministic in our official build environment!
That being said, the builds we ship to users are using PGO. And an end-to-end build involving PGO is intrinsically not deterministic because it relies on timing data that varies from one run to the next. And we don't yet have continuous automated end-to-end testing that determinism holds. But the underlying infrastructure to support deterministic and reproducible Firefox builds is there and is not going away. I think that's a milestone worth celebrating.
This milestone required the effort of many people, often working indirectly toward it. Debian's reproducible builds effort gave us an operating system that provided deterministic and reproducible guarantees. Switching Firefox CI to Taskcluster enabled us to switch to Debian relatively easily. Many were involved with non-determinism fixes in Firefox over the years. But Mike Hommey drove the transition of the build environment to Debian and he deserves recognition for his individual contribution. Thanks to all these efforts - and especially Mike Hommey's - we can now say Firefox builds deterministically!
The fx-reproducible-build bug tracks ongoing efforts to further improve the reproducibility story of Firefox. (~300 bugs in its dependency tree have already been resolved!)
Scaling Firefox Development Workflows
May 16, 2018 at 04:10 PM | categories: MozillaOne of the central themes of my time at Mozilla has been my pursuit of making it easier to contribute to and hack on Firefox.
I vividly remember my first day at Mozilla in 2011 when I went to build Firefox for the first time. I thought the entire experience - from obtaining the source code, installing build dependencies, building, running tests, submitting patches for review, etc was quite... lacking. When I asked others if they thought this was an issue, many rightfully identified problems (like the build system being slow). But there was a significant population who seemed to be naive and/or apathetic to the breadth of the user experience shortcomings. This is totally understandable: the scope of the problem is immense and various people don't have the perspective, are blinded/biased by personal experience, and/or don't have the product design or UX experience necessary to comprehend the problem.
When it comes to contributing to Firefox, I think the problems have as much to do with user experience (UX) as they do with technical matters. As I wrote in 2012, user experience matters and developers are people too. You can have a technically superior product, but if the UX is bad, you will have a hard time attracting and retaining new users. And existing users won't be as happy. These are the kinds of problems that a product manager or designer deals with. A difference is that in the case of Firefox development, the target audience is a very narrow and highly technically-minded subset of the larger population - much smaller than what your typical product targets. The total addressable population is (realistically) in the thousands instead of millions. But this doesn't mean you ignore the principles of good product design when designing developer tooling. When it comes to developer tooling and workflows, I think it is important to have a product manager mindset and treat it not as a collection of tools for technically-minded individuals, but as a product having an overall experience. You only have to look as far as the Firefox Developer Tools to see this approach applied and the positive results it has achieved.
Historically, Mozilla has lacked a formal team with the domain expertise
and mandate to treat Firefox contribution as a product. We didn't have
anything close to this until a few years ago. Before we had such a team,
I took on some of these problems individually. In 2012, I wrote mach - a
generic CLI command dispatch tool - to provide a central, convenient,
and easy-to-use command to discover development actions and to run them.
(Read the announcement blog post for
some historical context.) I also
introduced
a one-line bootstrap tool (now mach bootstrap) to make it easier to
configure your machine for building Firefox. A few months later, I
was responsible for
introducing moz.build files,
which paved the way for countless optimizations and for rearchitecting
the Firefox build system to use modern tools - a project that is still
ongoing (digging out from ~two decades of technical debt is a massive
effort). And a few months after that, I started going down the version
control rabbit hole and improving matters there. And I was also heavily
involved with MozReview for improving the code review experience.
Looking back, I was responsible for and participated in a ton of foundational changes to how Firefox is developed. Of course, dozens of others have contributed to getting us to where we are today and I can't and won't take credit for the hard work of others. Nor will I claim I was the only person coming up with good ideas or transforming them into reality. I can name several projects (like Taskcluster and Treeherder) that have been just as or more transformational than the changes I can take credit for. It would be vain and naive of me to elevate my contributions on a taller pedestal and I hope nobody reads this and thinks I'm doing that.
(On a personal note, numerous people have told me that things like mach
and the bootstrap tool have transformed the Firefox contribution experience
for the better. I've also had very senior people tell me that they don't
understand why these tools are important and/or are skeptical of the need
for investments in this space. I've found this dichotomy perplexing and
troubling. Because some of the detractors (for lack of a better word) are
highly influential and respected, their apparent skepticism sews seeds of
doubt and causes me to second guess my contributions and world view. This
feels like a form or variation of imposter syndrome and it is something I
have struggled with during my time at Mozilla.)
From my perspective, the previous five or so years in Firefox development
workflows has been about initiating foundational changes and executing on
them. When it was introduced, mach was radical. It didn't do much and
its use was optional. Now almost everyone uses it. Similar stories have
unfolded for Taskcluster, MozReview, and various other tools and
platforms. In other words, we laid a foundation and have been steadily
building upon it for the past several years. That's not to say other
foundational changes haven't occurred since (they have - the imminent switch
to Phabricator is a terrific example). But the volume of foundational
changes has slowed since 2012-2014. (I think this is due to Mozilla
deciding to invest more in tools as a result of growing pains from
significant company expansion that began in 2010. With that investment, we
invested in the bigger ticket long-standing workflow pain points, such as
CI (Taskcluster), the Firefox build system, Treeherder, and code review.)
Workflows Today and in the Future
Over the past several years, the size, scope, and complexity of Firefox development activities has increased.
One way to see this is at the source code level. The following chart shows the size of the mozilla-central version control repository over time.
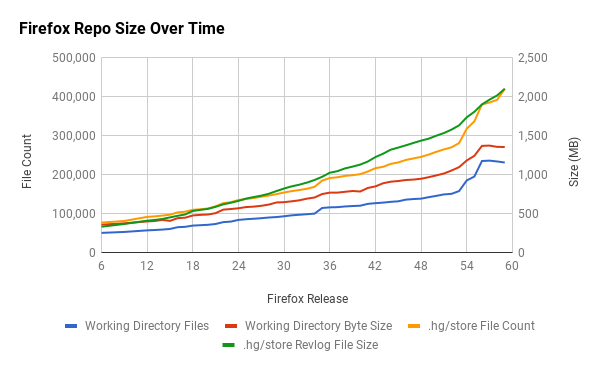
The size increases are obvious. The increases cumulatively represent new features, technologies, and workflows. For example, the repository contains thousands of Web Platform Tests (WPT) files, a shared test suite for web platform implementations, like Gecko and Blink. WPT didn't exist a few years ago. Now we have files under source control, tools for running those tests, and workflows revolving around changing those tests. The incorporation of Rust and components of Servo into Firefox is also responsible for significant changes. Firefox features such as Developer Tools have been introduced or ballooned in size in recent years. The Go Faster project and the move to system add-ons has introduced various new workflows and challenges for testing Firefox.
Many of these changes are building upon the user-facing foundational
workflow infrastructure that was last significantly changed in 2012-2014.
This has definitely contributed to some growing pains. For example, there
are now 92 mach commands instead of like 5. mach help - intended to
answer what can I do and how should I do it - is overwhelming, especially
to new users. The repository is around 2 gigabytes of data to clone instead
of around 500 megabytes. We have 240,000 files in a full checkout instead
of 70,000 files. There's a ton of new pieces floating around. Any
product manager tasked with user acquisition and retention will tell you
that increasing the barrier to entry and use will jeopardize these
outcomes. But with the growth of Firefox's technical underbelly in the
previous years, we've made it harder to contribute by requiring users to
download and see a lot more files (version control) and be overwhelmed
by all the options for actions to take (mach having 92 commands). And
as the sheer number of components constituting Firefox increases, it
becomes harder and harder for everyone - not just new contributors - to
reason about how everything fits together.
I've been framing this general problem as scaling Firefox development workflows and every time I think about the high-level challenges facing Firefox contribution today and in the years ahead, this problem floats to the top of my list of concerns. Yes, we have pressing issues like improving the code review experience and making the Firefox build system and Taskcluster-based CI fast, efficient, and reliable. But even if you make these individual pieces great, there is still a cross-domain problem of how all these components weave together. This is why I think it is important to take a wholistic view and treat developer workflow as a product.
When I look at this the way a product manager or designer would, I see a few fundamental problems that need addressing.
First, we're not optimizing for comprehensive end-to-end workflows. By and large, we're designing our tools in isolation. We focus more on maximizing the individual components instead of maximizing the interaction between them. For example, Taskcluster and Treeherder are pretty good in isolation. But we're missing features like Treeherder being able to tell me the command to run locally to reproduce a failure: I want to see a failure on Treeherder and be able to copy and paste commands into my terminal to debug the failure. In the case of code review, we've designed two good code review tools (MozReview and Phabricator) but we haven't invested in making submitting code reviews turn key (the initial system configuration is difficult and we still don't have things like automatic bug filing or reviewer selection). We are leaving many workflow optimizations on the table by not implementing thoughtful tie-ins and transitions between various tools.
Second, by-and-large we're still optimizing for a single, monolithic user
segment instead of recognizing and optimizing for different users and
their workflow requirements. For example, mach help lists 92 commands.
I don't think any single person cares about all 92 of those commands. The
average person may only care about 10 or even 20. In terms of user
interface design, the features and workflow requirements of small user
segments are polluting the interface for all users and making the entire
experience complicated and difficult to reason about. As a concrete
example, why should a system add-on developer or a Firefox Developer Tools
developer (these people tend to care about testing a standalone Firefox
add-on) care about Gecko's build system or tests? If you aren't touching
Gecko or Firefox's chrome code, why should you be exposed to workflows
and requirements that don't have a major impact on you? Or something more
extreme, if you are developing a standalone Rust module or Python package
in mozilla-central, why do you need to care about Firefox at all? (Yes,
Firefox or another downstream consumer may care about changes to that
standalone component and you can't ignore those dependencies. But it
should at least be possible to hide those dependencies.)
Waving my hands, the solution to these problems is to treat Firefox development workflow as a product and to apply the same rigor that we use for actual Firefox product development. Give people with a vision for the entire workflow the ability to prioritize investment across tools and platforms. Give them a process for defining features that work across tools. Perform formal user studies. See how people are actually using the tools you build. Bring in design and user experience experts to help formulate better workflows. Perform user typing so different, segmentable workflows can be optimized for. Treat developers as you treat users of real products: listen to them. Give developers a voice to express frustrations. Let them tell you what they are trying to do and what they wish they could do. Integrate this feedback into a feature roadmap. Turn common feedback into action items for new features.
If you think these ideas are silly and it doesn't make sense to apply a product mindset to developer workflows and tooling, then you should be asking whether product management and all that it entails is also a silly idea. If you believe that aspects of product management have beneficial outcomes (which most companies do because otherwise there wouldn't be product managers), then why wouldn't you want to apply the methods of that discipline to developers and development workflows? Developers are users too and the fact that they work for the same company that is creating the product shouldn't make them immune from the benefits of product management.
If we want to make contributing to Firefox an even better experience for Mozilla employees and community contributors, I think we need to take a step back and assess the situation as a product manager would. The improvements that have been made to the individual pieces constituting Firefox's development workflow during my nearly seven years at Mozilla have been incredible. But I think in order to achieve the next round of major advancements in workflow productivity, we'll need to focus on how all of the pieces fit together. And that requires treating the entire workflow as a cohesive product.
Next Page »