High-level Problems with Git and How to Fix Them
December 11, 2017 at 10:30 AM | categories: Git, Mercurial, MozillaI have a... complicated relationship with Git.
When Git first came onto the scene in the mid 2000's, I was initially skeptical because of its horrible user interface. But once I learned it, I appreciated its speed and features - especially the ease at which you could create feature branches, merge, and even create commits offline (which was a big deal in the era when Subversion was the dominant version control tool in open source and you needed to speak with a server in order to commit code). When I started using Git day-to-day, it was such an obvious improvement over what I was using before (mainly Subversion and even CVS).
When I started working for Mozilla in 2011, I was exposed to the Mercurial version control, which then - and still today - hosts the canonical repository for Firefox. I didn't like Mercurial initially. Actually, I despised it. I thought it was slow and its features lacking. And I frequently encountered repository corruption.
My first experience learning the internals of both Git and Mercurial came when I found myself hacking on hg-git - a tool that allows you to convert Git and Mercurial repositories to/from each other. I was hacking on hg-git so I could improve the performance of converting Mercurial repositories to Git repositories. And I was doing that because I wanted to use Git - not Mercurial - to hack on Firefox. I was trying to enable an unofficial Git mirror of the Firefox repository to synchronize faster so it would be more usable. The ulterior motive was to demonstrate that Git is a superior version control tool and that Firefox should switch its canonical version control tool from Mercurial to Git.
In what is a textbook definition of irony, what happened instead was I actually learned how Mercurial worked, interacted with the Mercurial Community, realized that Mozilla's documentation and developer practices were... lacking, and that Mercurial was actually a much, much more pleasant tool to use than Git. It's an old post, but I summarized my conversion four and a half years ago. This started a chain of events that somehow resulted in me contributing a ton of patches to Mercurial, taking stewardship of hg.mozilla.org, and becoming a member of the Mercurial Steering Committee - the governance group for the Mercurial Project.
I've been an advocate of Mercurial over the years. Some would probably say I'm a Mercurial fanboy. I reject that characterization because fanboy has connotations that imply I'm ignorant of realities. I'm well aware of Mercurial's faults and weaknesses. I'm well aware of Mercurial's relative lack of popularity, I'm well aware that this lack of popularity almost certainly turns away contributors to Firefox and other Mozilla projects because people don't want to have to learn a new tool. I'm well aware that there are changes underway to enable Git to scale to very large repositories and that these changes could threaten Mercurial's scalability advantages over Git, making choices to use Mercurial even harder to defend. (As an aside, the party most responsible for pushing Git to adopt architectural changes to enable it to scale these days is Microsoft. Could anyone have foreseen that?!)
I've achieved mastery in both Git and Mercurial. I know their internals and their command line interfaces extremely well. I understand the architecture and principles upon which both are built. I'm also exposed to some very experienced and knowledgeable people in the Mercurial Community. People who have been around version control for much, much longer than me and have knowledge of random version control tools you've probably never heard of. This knowledge and exposure allows me to make connections and see opportunities for version control that quite frankly most do not.
In this post, I'll be talking about some high-level, high-impact problems with Git and possible solutions for them. My primary goal of this post is to foster positive change in Git and the services around it. While I personally prefer Mercurial, improving Git is good for everyone. Put another way, I want my knowledge and perspective from being part of a version control community to be put to good wherever it can.
Speaking of Mercurial, as I said, I'm a heavy contributor and am somewhat influential in the Mercurial Community. I want to be clear that my opinions in this post are my own and I'm not speaking on behalf of the Mercurial Project or the larger Mercurial Community. I also don't intend to claim that Mercurial is holier-than-thou. Mercurial has tons of user interface failings and deficiencies. And I'll even admit to being frustrated that some systemic failings in Mercurial have gone unaddressed for as long as they have. But that's for another post. This post is about Git. Let's get started.
The Staging Area
The staging area is a feature that should not be enabled in the default Git configuration.
Most people see version control as an obstacle standing in the way of accomplishing some other task. They just want to save their progress towards some goal. In other words, they want version control to be a save file feature in their workflow.
Unfortunately, modern version control tools don't work that way. For starters, they require people to specify a commit message every time they save. This in of itself can be annoying. But we generally accept that as the price you pay for version control: that commit message has value to others (or even your future self). So you must record it.
Most people want the barrier to saving changes to be effortless. A commit message is already too annoying for many users! The Git staging area establishes a higher barrier to saving. Instead of just saving your changes, you must first stage your changes to be saved.
If you requested save in your favorite GUI application, text editor, etc and it popped open a select the changes you would like to save dialog, you would rightly think just save all my changes already, dammit. But this is exactly what Git does with its staging area! Git is saying I know all the changes you made: now tell me which changes you'd like to save. To the average user, this is infuriating because it works in contrast to how the save feature works in almost every other application.
There is a counterargument to be made here. You could say that the editor/application/etc is complex - that it has multiple contexts (files) - that each context is independent - and that the user should have full control over which contexts (files) - and even changes within those contexts - to save. I agree: this is a compelling feature. However, it isn't an appropriate default feature. The ability to pick which changes to save is a power-user feature. Most users just want to save all the changes all the time. So that should be the default behavior. And the Git staging area should be an opt-in feature.
If intrinsic workflow warts aren't enough, the Git staging area has a
horrible user interface. It is often referred to as the cache
for historical reasons.
Cache of course means something to anyone who knows anything about
computers or programming. And Git's use of cache doesn't at all align
with that common definition. Yet the the terminology in Git persists.
You have to run commands like git diff --cached to examine the state
of the staging area. Huh?!
But Git also refers to the staging area as the index. And this
terminology also appears in Git commands! git help commit has numerous
references to the index. Let's see what git help glossary has to say::
index
A collection of files with stat information, whose contents are
stored as objects. The index is a stored version of your working tree.
Truth be told, it can also contain a second, and even a third
version of a working tree, which are used when merging.
index entry
The information regarding a particular file, stored in the index.
An index entry can be unmerged, if a merge was started, but not
yet finished (i.e. if the index contains multiple versions of that
file).
In terms of end-user documentation, this is a train wreck. It tells the
lay user absolutely nothing about what the index actually is. Instead,
it casually throws out references to stat information (requires the user
know what the stat() function call and struct are) and objects (a Git
term for a piece of data stored by Git). It even undermines its own credibility
with that truth be told sentence. This definition is so bad that it
would probably improve user understanding if it were deleted!
Of course, git help index says No manual entry for gitindex. So
there is literally no hope for you to get a concise, understandable
definition of the index. Instead, it is one of those concepts that you
think you learn from interacting with it all the time. Oh, when I
git add something it gets into this state where git commit will
actually save it.
And even if you know what the Git staging area/index/cached is, it can
still confound you. Do you know the interaction between uncommitted
changes in the staging area and working directory when you git rebase?
What about git checkout? What about the various git reset invocations?
I have a confession: I can't remember all the edge cases either. To play
it safe, I try to make sure all my outstanding changes are committed
before I run something like git rebase because I know that will be
safe.
The Git staging area doesn't have to be this complicated. A re-branding
away from index to staging area would go a long way. Adding an alias
from git diff --staged to git diff --cached and removing references
to the cache from common user commands would make a lot of sense and
reduce end-user confusion.
Of course, the Git staging area doesn't really need to exist at all!
The staging area is essentially a soft commit. It performs the
save progress role - the basic requirement of a version control tool.
And in some aspects it is actually a better save progress implementation
than a commit because it doesn't require you to type a commit message!
Because the staging area is a soft commit, all workflows using it can
be modeled as if it were a real commit and the staging area didn't
exist at all! For example, instead of git add --interactive +
git commit, you can run git commit --interactive. Or if you wish
to incrementally add new changes to an in-progress commit, you can
run git commit --amend or git commit --amend --interactive or
git commit --amend --all. If you actually understand the various modes
of git reset, you can use those to uncommit. Of course, the user
interface to performing these actions in Git today is a bit convoluted.
But if the staging area didn't exist, new high-level commands like
git amend and git uncommit could certainly be invented.
To the average user, the staging area is a complicated concept. I'm a power user. I understand its purpose and how to harness its power. Yet when I use Mercurial (which doesn't have a staging area), I don't miss the staging area at all. Instead, I learn that all operations involving the staging area can be modeled as other fundamental primitives (like commit amend) that you are likely to encounter anyway. The staging area therefore constitutes an unnecessary burden and cognitive load on users. While powerful, its complexity and incurred confusion does not justify its existence in the default Git configuration. The staging area is a power-user feature and should be opt-in by default.
Branches and Remotes Management is Complex and Time-Consuming
When I first used Git (coming from CVS and Subversion), I thought branches and remotes were incredible because they enabled new workflows that allowed you to easily track multiple lines of work across many repositories. And ~10 years later, I still believe the workflows they enable are important. However, having amassed a broader perspective, I also believe their implementation is poor and this unnecessarily confuses many users and wastes the time of all users.
My initial zen moment with Git - the time when Git finally clicked for me -
was when I understood Git's object model: that Git is just a
content indexed key-value store consisting of a different object types
(blobs, trees, and commits) that have a particular relationship with
each other. Refs are symbolic names pointing to Git commit objects. And
Git branches - both local and remote - are just refs having a
well-defined naming convention (refs/heads/<name> for local branches and
refs/remotes/<remote>/<name> for remote branches). Even tags and
notes are defined via refs.
Refs are a necessary primitive in Git because the Git storage model is to throw all objects into a single, key-value namespace. Since the store is content indexed and the key name is a cryptographic hash of the object's content (which for all intents and purposes is random gibberish to end-users), the Git store by itself is unable to locate objects. If all you had was the key-value store and you wanted to find all commits, you would need to walk every object in the store and read it to see if it is a commit object. You'd then need to buffer metadata about those objects in memory so you could reassemble them into say a DAG to facilitate looking at commit history. This approach obviously doesn't scale. Refs short-circuit this process by providing pointers to objects of importance. It may help to think of the set of refs as an index into the Git store.
Refs also serve another role: as guards against garbage collection. I won't go into details about loose objects and packfiles, but it's worth noting that Git's key-value store also behaves in ways similar to a generational garbage collector like you would find in programming languages such as Java and Python. The important thing to know is that Git will garbage collect (read: delete) objects that are unused. And the mechanism it uses to determine which objects are unused is to iterate through refs and walk all transitive references from that initial pointer. If there is an object in the store that can't be traced back to a ref, it is unreachable and can be deleted.
Reflogs maintain the history of a value for a ref: for each ref they contain a log of what commit it was pointing to, when that pointer was established, who established it, etc. Reflogs serve two purposes: facilitating undoing a previous action and holding a reference to old data to prevent it from being garbage collected. The two use cases are related: if you don't care about undo, you don't need the old reference to prevent garbage collection.
This design of Git's store is actually quite sensible. It's not perfect (nothing is). But it is a solid foundation to build a version control tool (or even other data storage applications) on top of.
The title of this section has to do with sub-optimal branches and remotes management. But I've hardly said anything about branches or remotes! And this leads me to my main complaint about Git's branches and remotes: that they are very thin veneer over refs. The properties of Git's underlying key-value store unnecessarily bleed into user-facing concepts (like branches and remotes) and therefore dictate sub-optimal practices. This is what's referred to as a leaky abstraction.
I'll give some examples.
As I stated above, many users treat version control as a save file step in their workflow. I believe that any step that interferes with users saving their work is user hostile. This even includes writing a commit message! I already argued that the staging area significantly interferes with this critical task. Git branches do as well.
If we were designing a version control tool from scratch (or if you were
a new user to version control), you would probably think that a sane
feature/requirement would be to update to any revision and start making
changes. In Git speak, this would be something like
git checkout b201e96f, make some file changes, git commit. I think
that's a pretty basic workflow requirement for a version control tool.
And the workflow I suggested is pretty intuitive: choose the thing to
start working on, make some changes, then save those changes.
Let's see what happens when we actually do this:
$ git checkout b201e96f
Note: checking out 'b201e96f'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at b201e96f94... Merge branch 'rs/config-write-section-fix' into maint
$ echo 'my change' >> README.md
$ git commit -a -m 'my change'
[detached HEAD aeb0c997ff] my change
1 file changed, 1 insertion(+)
$ git push indygreg
fatal: You are not currently on a branch.
To push the history leading to the current (detached HEAD)
state now, use
git push indygreg HEAD:<name-of-remote-branch>
$ git checkout master
Warning: you are leaving 1 commit behind, not connected to
any of your branches:
aeb0c997ff my change
If you want to keep it by creating a new branch, this may be a good time
to do so with:
git branch <new-branch-name> aeb0c997ff
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
I know what all these messages mean because I've mastered Git. But if you were a newcomer (or even a seasoned user), you might be very confused. Just so we're on the same page, here is what's happening (along with some commentary).
When I run git checkout b201e96f, Git is trying to tell me that I'm
potentially doing something that could result in the loss of my data. A
golden rule of version control tools is don't lose the user's data. When
I run git checkout, Git should be stating the risk for data loss very
clearly. But instead, the If you want to create a new branch sentence is
hiding this fact by instead phrasing things around retaining commits you
create rather than the possible loss of data. It's up to the user
to make the connection that retaining commits you create actually means
don't eat my data. Preventing data loss is critical and Git should not
mince words here!
The git commit seems to work like normal. However, since we're in a
detached HEAD state (a phrase that is likely gibberish to most users),
that commit isn't referred to by any ref, so it can be lost easily.
Git should be telling me that I just committed something it may not
be able to find in the future. But it doesn't. Again, Git isn't being
as protective of my data as it needs to be.
The failure in the git push command is essentially telling me I need
to give things a name in order to push. Pushing is effectively remote
save. And I'm going to apply my reasoning about version control tools
not interfering with save to pushing as well: Git is adding an
extra barrier to remote save by refusing to push commits without a
branch attached and by doing so is being user hostile.
Finally, we git checkout master to move to another commit. Here, Git
is actually doing something halfway reasonable. It is telling me I'm
leaving commits behind, which commits those are, and the command to
use to keep those commits. The warning is good but not great. I think
it needs to be stronger to reflect the risk around data loss if that
suggested Git commit isn't executed. (Of course, the reflog for HEAD
will ensure that data isn't immediately deleted. But users shouldn't
need to involve reflogs to not lose data that wasn't rewritten.)
The point I want to make is that Git doesn't allow you to just update and save. Because its dumb store requires pointers to relevant commits (refs) and because that requirement isn't abstracted away or paved over by user-friendly features in the frontend, Git is effectively requiring end-users to define names (branches) for all commits. If you fail to define a name, it gets a lot harder to find your commits, exchange them, and Git may delete your data. While it is technically possible to not create branches, the version control tool is essentially unusable without them.
When local branches are exchanged, they appear as remote branches to others. Essentially, you give each instance of the repository a name (the remote). And branches/refs fetched from a named remote appear as a ref in the ref namespace for that remote. e.g. refs/remotes/origin holds refs for the origin remote. (Git allows you to not have to specify the refs/remotes part, so you can refer to e.g. refs/remotes/origin/master as origin/master.)
Again, if you were designing a version control tool from scratch or you
were a new Git user, you'd probably think remote refs would make
good starting points for work. For example, if you know you should be
saving new work on top of the master branch, you might be inclined
to begin that work by running git checkout origin/master. But like
our specific-commit checkout above:
$ git checkout origin/master
Note: checking out 'origin/master'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 95ec6b1b33... RelNotes: the eighth batch
This is the same message we got for a direct checkout. But we did
supply a ref/remote branch name. What gives? Essentially, Git tries
to enforce that the refs/remotes/ namespace is read-only and only
updated by operations that exchange data with a remote, namely git fetch,
git pull, and git push.
For this to work correctly, you need to create a new local branch
(which initially points to the commit that refs/remotes/origin/master
points to) and then switch/activate that local branch.
I could go on talking about all the subtle nuances of how Git branches are managed. But I won't.
If you've used Git, you know you need to use branches. You may or may
not recognize just how frequently you have to type a branch name into
a git command. I guarantee that if you are familiar with version control
tools and workflows that aren't based on having to manage refs to
track data, you will find Git's forced usage of refs and branches
a bit absurd. I half jokingly refer to Git as Game of Refs. I say that
because coming from Mercurial (which doesn't require you to name things),
Git workflows feel to me like all I'm doing is typing the names of branches
and refs into git commands. I feel like I'm wasting my precious
time telling Git the names of things only because this is necessary to
placate the leaky abstraction of Git's storage layer which requires
references to relevant commits.
Git and version control doesn't have to be this way.
As I said, my Mercurial workflow doesn't rely on naming things. Unlike Git, Mercurial's store has an explicit (not shared) storage location for commits (changesets in Mercurial parlance). And this data structure is ordered, meaning a changeset later always occurs after its parent/predecessor. This means that Mercurial can open a single file/index to quickly find all changesets. Because Mercurial doesn't need pointers to commits of relevance, names aren't required.
My Zen of Mercurial moment came when I realized you didn't have to name things in Mercurial. Having used Git before Mercurial, I was conditioned to always be naming things. This is the Git way after all. And, truth be told, it is common to name things in Mercurial as well. Mercurial's named branches were the way to do feature branches in Mercurial for years. Some used the MQ extension (essentially a port of quilt), which also requires naming individual patches. Git users coming to Mercurial were missing Git branches and Mercurial's bookmarks were a poor port of Git branches.
But recently, more and more Mercurial users have been coming to the realization that names aren't really necessary. If the tool doesn't actually require naming things, why force users to name things? As long as users can find the commits they need to find, do you actually need names?
As a demonstration, my Mercurial workflow leans heavily on the hg show work
and hg show stack commands. You will need to enable the show extension
by putting the following in your hgrc config file to use them:
[extensions]
show =
Running hg show work (I have also set the config
commands.show.aliasprefix=sto enable me to type hg swork) finds all
in-progress changesets and other likely-relevant changesets (those
with names and DAG heads). It prints a concise DAG of those changesets:

And hg show stack shows just the current line of work and its
relationship to other important heads:
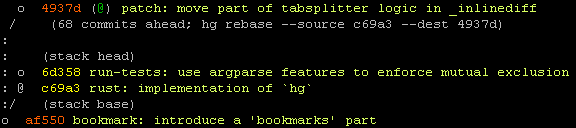
Aside from the @ bookmark/name set on that top-most changeset, there are
no names! (That @ comes from the remote repository, which has set that name.)
Outside of code archeology workflows, hg show work shows the changesets I
care about 95% of the time. With all I care about (my in-progress work and
possible rebase targets) rendered concisely, I don't have to name things
because I can just find whatever I'm looking for by running hg show work!
Yes, you need to run hg show work, visually scan for what you are looking
for, and copy a (random) hash fragment into a number of commands. This
sounds like a lot of work. But I believe it is far less work than naming
things. Only when you practice this workflow do you realize just how much
time you actually spend finding and then typing names in to hg and -
especailly - git commands! The ability to just hg update to a changeset
and commit without having to name things is just so liberating. It feels
like my version control tool is putting up fewer barriers and letting me
work quickly.
Another benefit of hg show work and hg show stack are that they present
a concise DAG visualization to users. This helps educate users about the
underlying shape of repository data. When you see connected nodes on a
graph and how they change over time, it makes it a lot easier to understand
concepts like merge and rebase.
This nameless workflow may sound radical. But that's because we're all
conditioned to naming things. I initially thought it was crazy as well. But
once you have a mechanism that gives you rapid access to data you care
about (hg show work in Mercurial's case), names become very optional. Now,
a pure nameless workflow isn't without its limitations. You want names
to identify the main targets for work (e.g. the master branch). And when
you exchange work with others, names are easier to work with, especially
since names survive rewriting. But in my experience, most of my commits
are only exchanged with me (synchronizing my in-progress commits across
devices) and with code review tools (which don't really need names and
can operate against raw commits). My most frequent use of names comes
when I'm in repository maintainer mode and I need to ensure commits
have names for others to reference.
Could Git support nameless workflows? In theory it can.
Git needs refs to find relevant commits in its store. And the wire protocol uses refs to exchange data. So refs have to exist for Git to function (assuming Git doesn't radically change its storage and exchange mechanisms to mitigate the need for refs, but that would be a massive change and I don't see this happening).
While there is a fundamental requirement for refs to exist, this doesn't necessarily mean that user-facing names must exist. The reason that we need branches today is because branches are little more than a ref with special behavior. It is theoretically possible to invent a mechanism that transparently maps nameless commits onto refs. For example, you could create a refs/nameless/ namespace that was automatically populated with DAG heads that didn't have names attached. And Git could exchange these refs just like it can branches today. It would be a lot of work to think through all the implications and to design and implement support for nameless development in Git. But I think it is possible.
I encourage the Git community to investigate supporting nameless workflows. Having adopted this workflow in Mercurial, Git's workflow around naming branches feels heavyweight and restrictive to me. Put another way, nameless commits are actually lighter-weight branches than Git branches! To the common user who just wants version control to be a save feature, requiring names establishes a barrier towards that goal. So removing the naming requirement would make Git simpler and more approachable to new users.
Forks aren't the Model You are Looking For
This section is more about hosted Git services (like GitHub, Bitbucket, and GitLab) than Git itself. But since hosted Git services are synonymous with Git and interaction with a hosted Git services is a regular part of a common Git user's workflow, I feel like I need to cover it. (For what it's worth, my experience at Mozilla tells me that a large percentage of people who say I prefer Git or we should use Git actually mean I like GitHub. Git and GitHub/Bitbucket/GitLab are effectively the same thing in the minds of many and anyone finding themselves discussing version control needs to keep this in mind because Git is more than just the command line tool: it is an ecosystem.)
I'll come right out and say it: I think forks are a relatively poor model for collaborating. They are light years better than what existed before. But they are still so far from the turn-key experience that should be possible. The fork hasn't really changed much since the current implementation of it was made popular by GitHub many years ago. And I view this as a general failure of hosted services to innovate.
So we have a shared understanding, a fork (as implemented on GitHub,
Bitbucket, GitLab, etc) is essentially a complete copy of a repository
(a git clone if using Git) and a fresh workspace for additional
value-added services the hosting provider offers (pull requests, issues,
wikis, project tracking, release tracking, etc). If you open the main
web page for a fork on these services, it looks just like the main
project's. You know it is a fork because there are cosmetics somewhere
(typically next to the project/repository name) saying forked from.
Before service providers adopted the fork terminology, fork was used in open source to refer to a splintering of a project. If someone or a group of people didn't like the direction a project was taking, wanted to take over ownership of a project because of stagnation, etc, they would fork it. The fork was based on the original (and there may even be active collaboration between the fork and original), but the intent of the fork was to create distance between the original project and its new incantation. A new entity that was sufficiently independent of the original.
Forks on service providers mostly retain this old school fork model. The fork gets a new copy of issues, wikis, etc. And anyone who forks establishes what looks like an independent incantation of a project. It's worth noting that the execution varies by service provider. For example, GitHub won't enable Issues for a fork by default, thereby encouraging people to file issues against the upstream project it was forked from. (This is good default behavior.)
And I know why service providers (initially) implemented things this
way: it was easy. If you are building a product, it's simpler to just
say a user's version of this project is a git clone and they get
a fresh database. On a technical level, this meets the traditional
definition of fork. And rather than introduce a new term into the
vernacular, they just re-purposed fork (albeit with softer
connotations, since the traditional fork commonly implied there
was some form of strife precipitating a fork).
To help differentiate flavors of forks, I'm going to define the terms soft fork and hard fork. A soft fork is a fork that exists for purposes of collaboration. The differentiating feature between a soft fork and hard fork is whether the fork is intended to be used as its own project. If it is, it is a hard fork. If not - if all changes are intended to be merged into the upstream project and be consumed from there - it is a soft fork.
I don't have concrete numbers, but I'm willing to wager that the vast majority of forks on Git service providers which have changes are soft forks rather than hard forks. In other words, these forks exist purely as a conduit to collaborate with the canonical/upstream project (or to facilitate a short-lived one-off change).
The current implementation of fork - which borrows a lot from its predecessor of the same name - is a good - but not great - way to facilitate collaboration. It isn't great because it technically resembles what you'd expect to see for hard fork use cases even though it is used predominantly with soft forks. This mismatch creates problems.
If you were to take a step back and invent your own version control
hosted service and weren't tainted by exposure to existing services
and were willing to think a bit beyond making it a glorified frontend
for the git command line interface, you might realize that the problem
you are solving - the product you are selling - is collaboration as
a service, not a Git hosting service. And if your product is
collaboration, then implementing your collaboration model around the
hard fork model with strong barriers between the original project and
its forks is counterproductive and undermines your own product.
But this is how GitHub, Bitbucket, GitLab, and others have implemented
their product!
To improve collaboration on version control hosted services, the concept of a fork needs to significantly curtailed. Replacing it should be a UI and workflow that revolves around the central, canonical repository.
You shouldn't need to create your own clone or fork of a repository in order to contribute. Instead, you should be able to clone the canonical repository. When you create commits, those commits should be stored and/or more tightly affiliated with the original project - not inside a fork.
One potential implementation is doable today. I'm going to call it workspaces. Here's how it would work.
There would exist a namespace for refs that can be controlled by
the user. For example, on GitHub (where my username is indygreg),
if I wanted to contribute to some random project, I would git push
my refs somewhere under refs/users/indygreg/ directly to that
project's. No forking necessary. If I wanted to contribute to a
project, I would just clone its repo then push to my workspace under
it. You could do this today by configuring your Git refspec properly.
For pushes, it would look something like
refs/heads/*:refs/users/indygreg/* (that tells Git to map local refs
under refs/heads/ to refs/users/indygreg/ on that remote repository).
If this became a popular feature, presumably the Git wire protocol could
be taught to advertise this feature such that Git clients automatically
configured themselves to push to user-specific workspaces attached to
the original repository.
There are several advantages to such a workspace model. Many of them revolve around eliminating forks.
At initial contribution time, no server-side fork is necessary in order to contribute. You would be able to clone and contribute without waiting for or configuring a fork. Or if you can create commits from the web interface, the clone wouldn't even be necessary! Lowering the barrier to contribution is a good thing, especially if collaboration is the product you are selling.
In the web UI, workspaces would also revolve around the source project and not be off in their own world like forks are today. People could more easily see what others are up to. And fetching their work would require typing in their username as opposed to configuring a whole new remote. This would bring communities closer and hopefully lead to better collaboration.
Not requiring forks also eliminates the need to synchronize your fork
with the upstream repository. I don't know about you, but one of the things
that bothers me about the Game of Refs that Git imposes is that I have
to keep my refs in sync with the upstream refs. When I fetch from
origin and pull down a new master branch, I need to git merge
that branch into my local master branch. Then I need to push that new
master branch to my fork. This is quite tedious. And it is easy to merge
the wrong branches and get your branch state out of whack. There are
better ways to map remote refs into your local names to make this far
less confusing.
Another win here is not having to push and store data multiple times.
When working on a fork (which is a separate repository), after you
git fetch changes from upstream, you need to eventually git push those
into your fork. If you've ever worked on a large repository and didn't
have a super fast Internet connection, you may have been stymied by
having to git push large amounts of data to your fork. This is quite
annoying, especially for people with slow Internet connections. Wouldn't
it be nice if that git push only pushed the data that was truly new and
didn't already exist somewhere else on the server? A workspace model
where development all occurs in the original repository would fix this.
As a bonus, it would make the storage problem on servers easier because
you would eliminate thousands of forks and you probably wouldn't have to
care as much about data duplication across repos/clones because the
version control tool solves a lot of this problem for you, courtesy of
having all data live alongside or in the original repository instead of
in a fork.
Another win from workspace-centric development would be the potential to do more user-friendly things after pull/merge requests are incorporated in the official project. For example, the ref in your workspace could be deleted automatically. This would ease the burden on users to clean up after their submissions are accepted. Again, instead of mashing keys to play the Game of Refs, this would all be taken care of for you automatically. (Yes, I know there are scripts and shell aliases to make this more turn-key. But user-friendly behavior shouldn't have to be opt-in: it should be the default.)
But workspaces aren't all rainbows and unicorns. There are access control concerns. You probably don't want users able to mutate the workspaces of other users. Or do you? You can make a compelling case that project administrators should have that ability. And what if someone pushes bad or illegal content to a workspace and you receive a cease and desist? Can you take down just the offending workspace while complying with the order? And what happens if the original project is deleted? Do all its workspaces die with it? These are not trivial concerns. But they don't feel impossible to tackle either.
Workspaces are only one potential alternative to forks. And I can come up with multiple implementations of the workspace concept. Although many of them are constrained by current features in the Git wire protocol. But Git is (finally) getting a more extensible wire protocol, so hopefully this will enable nice things.
I challenge Git service providers like GitHub, Bitbucket, and GitLab to think outside the box and implement something better than how forks are implemented today. It will be a large shift. But I think users will appreciate it in the long run.
Conclusion
Git is an ubiquitous version control tool. But it is frequently lampooned for its poor usability and documentation. We even have research papers telling us which parts are bad. Nobody I know has had a pleasant initial experience with Git. And it is clear that few people actually understand Git: most just know the command incantations they need to know to accomplish a small set of common activities. (If you are such a person, there is nothing to be ashamed about: Git is a hard tool.)
Popular Git-based hosting and collaboration services (such as GitHub,
Bitbucket, and GitLab) exist. While they've made strides to make it
easier to commit data to a Git repository (I purposefully avoid saying
use Git because the most usable tools seem to avoid the git command
line interface as much as possible), they are often a thin veneer over
Git itself (see forks). And Git is a thin veneer over a content
indexed key-value store (see forced usage of bookmarks).
As an industry, we should be concerned about the lousy usability of Git and the tools and services that surround it. Some may say that Git - with its near monopoly over version control mindset - is a success. I have a different view: I think it is a failure that a tool with a user experience this bad has achieved the success it has.
The cost to Git's poor usability can be measured in tens if not hundreds of millions of dollars in time people have wasted because they couldn't figure out how to use Git. Git should be viewed as a source of embarrassment, not a success story.
What's really concerning is that the usability problems of Git have been known for years. Yet it is as popular as ever and there have been few substantial usability improvements. We do have some alternative frontends floating around. But these haven't caught on.
I'm at a loss to understand how an open source tool as popular as Git has remained so mediocre for so long. The source code is out there. Anybody can submit a patch to fix it. Why is it that so many people get tripped up by the same poor usability issues years after Git became the common version control tool? It certainly appears that as an industry we have been unable or unwilling to address systemic deficiencies in a critical tool. Why this is, I'm not sure.
Despite my pessimism about Git's usability and its poor track record of being attentive to the needs of people who aren't power users, I'm optimistic that the future will be brighter. While the ~7000 words in this post pale in comparison to the aggregate word count that has been written about Git, hopefully this post strikes a nerve and causes positive change. Just because one generation has toiled with the usability problems of Git doesn't mean the next generation has to suffer through the same. Git can be improved and I encourage that change to happen. The three issues above and their possible solutions would be a good place to start.