A Crazy Day
December 04, 2014 at 11:34 PM | categories: MozillaToday was one crazy day.
The build peers all sat down with Release Engineering and Axel Hecht to talk l10n packaging. Mike Hommey has a Q1 goal to fix l10n packaging. There is buy-in from Release Engineering on enabling him in his quest to slay dragons. This will make builds faster and will pay off a massive mountain of technical debt that plagues multiple groups at Mozilla.
The Firefox build system contributors sat down with a bunch of Rust people and we talked about what it would take to integrate Rust into the Firefox build system and the path towards shipping a Rust component in Firefox. It sounds like that is going to happen in 2015 (although we're not yet sure what component will be written in Rust). I consider it an achievement that the gathering of both groups didn't result in infinite rabbit holing about system architectures, toolchains, and the build people telling horror stories to wide-eyed Rust people about the crazy things we have to do to build and ship Firefox. Believe me, the temptation was there.
People interested in the build system all sat down and reflected on the state of the build system and where we want to go. We agreed to create a build mode optimized for non-Gecko developers that downloads pre-built binaries - avoiding ~10 minutes of C/C++ compile time for builds. Mark my words, this will be one of those changes that once deployed will cause people to say "I can't believe we went so long without this."
I joined Mark Côté and others to talk about priorities for MozReview. We'll be making major improvements to the UX and integrating static analysis into reviews. Push a patch for review and have machines do some of the work that humans are currently doing! We're tentatively planning a get-together in Toronto in January to sprint towards awesomeness.
I ended the day by giving a long and rambling presentation about version control, with emphasis on Mercurial. I can't help but feel that I talked way too much. There's just so much knowledge to cover. A few people told me afterwards they learned a lot. I'd appreciate feedback if you attended. Anyway, I got a few nods from people as I was saying some somewhat contentious things. It's always good to have validation that I'm not on an island when I say crazy things.
I hope to spend Friday chasing down loose ends from the week. This includes talking to some security gurus about another crazy idea of mine to integrate PGP into the code review and code landing workflow for Firefox. I'll share more details once I get a professional opinion on the security front.
The Mozlandia Tree Outage and Code Review
December 04, 2014 at 08:40 AM | categories: MozReview, Mozilla, code reviewYou may have noticed the Firefox trees were closed for the better part of yesterday.
Long story short, a file containing URLs for Firefox installers was updated to reference https://ftp.mozilla.org/ from http://download-installer.cdn.mozilla.net/. The original, latter host is a CDN. The former is not. When thousands of clients started hitting ftp.mozilla.org, it overwhelmed the servers and network, causing timeouts and other badness.
The change in question was accidental. It went through code review. From a code change standpoint, procedures were followed.
It is tempting to point fingers at the people involved. However, I want us to consider placing blame elsewhere: on the code review tool.
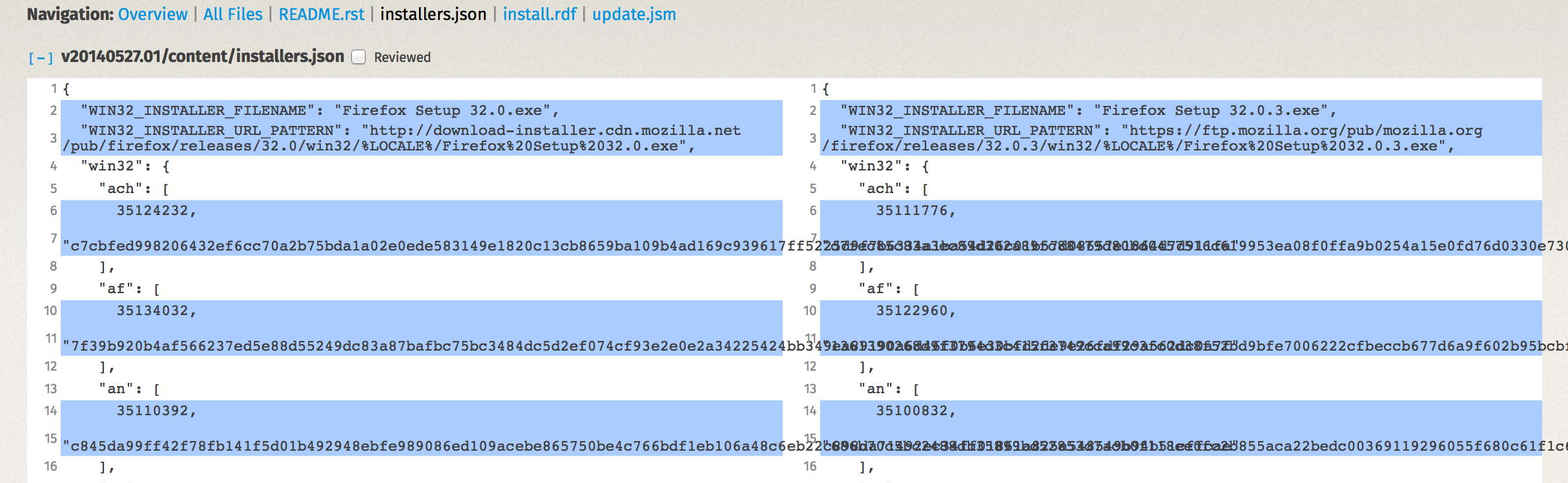
The diff being reviewed was to change the Firefox version number from 32.0 to 32.0.3. If you were asked to review this patch, I'm guessing your eyes would have glanced over everything in the URL except the version number part. I'm pretty sure mine would have.
Let's take a look at what the reviewer saw in Bugzilla/Splinter (click to see full size):
And here is what the reviewer would have seen had the review been conducted in MozReview:
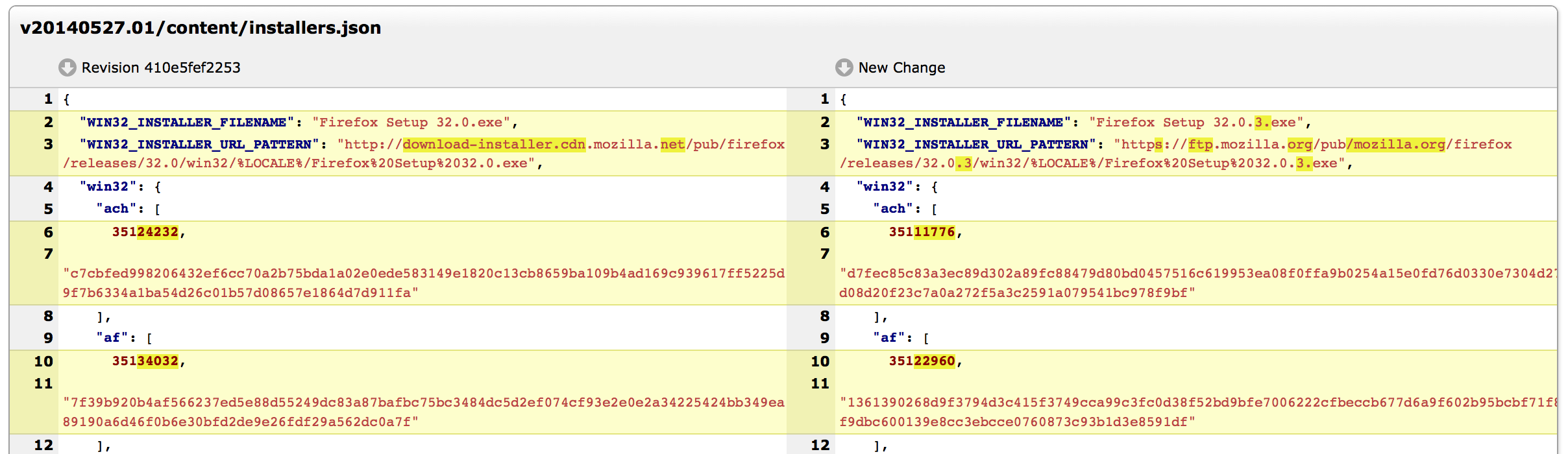
Which tool makes the change of hostname more obvious? Bugzilla/Splinter or MozReview?
MozReview's support for intraline diffs more clearly draws attention to the hostname change. I posit that had this patch been reviewed with MozReview, the chances are greater we wouldn't have had a network outage yesterday.
And it isn't just intraline diffs that make Splinter/Bugzilla a sub-optimal code review tool. I recently blogged about the numerous ways that using Bugzilla for code revie results in harder reviews and buggier code. Every day we continue using Bugzilla/Splinter instead of investing in better code review tools is a day severe bugs like this can and will slip through the cracks.
If there is any silver lining to this outage, I hope it is that we need to double down on our investment in developer tools, particularly code review.
Test Drive the New Headless Try Repository
November 20, 2014 at 02:45 PM | categories: Mercurial, MozillaMercurial and Git both experience scaling pains as the number of heads in a repository approaches infinity. Operations like push and pull slow to a crawl and everyone gets frustrated.
This is the problem Mozilla's Try repository has been dealing with for years. We know the solution doesn't scale. But we've been content kicking the can by resetting the repository (blowing away data) to make the symptoms temporarily go away.
One of my official goals is to ship a scalable Try solution by the end of 2014.
Today, I believe I finally have enough code cobbled together to produce a working concept. And I could use your help testing it.
I would like people to push their Try, code review, and other miscellaneous heads to a special repository. To do this:
$ hg push -r . -f ssh://hg@hg.gregoryszorc.com/gecko-headless
That is:
- Consider the changeset belonging to the working copy
- Allow the creation of new heads
- Send it to the gecko-headless repo on hg.gregoryszorc.com using SSH
Here's what happening.
I have deployed a special repository to my personal server that I believe will behave very similarly to the final solution.
When you push to this repository, instead of your changesets being applied directly to the repository, it siphons them off to a Mercurial bundle. It then saves this bundle somewhere along with some metadata describing what is inside.
When you run hg pull -r
Things this repository doesn't do:
- This repository will not actually send changesets to Try for you.
- You cannot
hg pullorhg clonethe repository and get all of the commits from bundles. This isn't a goal. It will likely never be supported. - We do not yet record a pushlog entry for pushes to the repository.
- The hgweb HTML interface does not yet handle commits that only exist in bundles. People want this to work. It will eventually work.
- Pulling from the repository over HTTP with a vanilla Mercurial install may not preserve phase data.
The purpose of this experiment is to expose the repository to some actual traffic patterns so I can see what's going on and get a feel for real-world performance, variability, bugs, etc. I plan to do all of this in the testing environment. But I'd like some real-world use on the actual Firefox repository to give me peace of mind.
Please report any issues directly to me. Leave a comment here. Ping me on IRC. Send me an email. etc.
Update 2014-11-21: People discovered a bug with pushed changesets accidentally being advanced to the public phase, despite the repository being non-publishing. I have fixed the issue. But you must now push to the repository over SSH, not HTTP.
Mercurial Server Hiccup 2014-11-06
November 07, 2014 at 11:00 AM | categories: Mercurial, MozillaWe had a hiccup on hg.mozilla.org yesterday. It resulted in prolonged tree closures for Firefox. Bug 1094922 tracks the issue.
What Happened
We noticed that many HTTP requests to hg.mozilla.org were getting 503 responses. On initial glance, the servers were healthy. CPU was below 100% utilization, I/O wait was reasonable. And there was little to no swapping. Furthermore, the logs showed a healthy stream of requests being successfully processed at levels that are typical. In other words, it looked like business as usual on the servers.
Upon deeper investigation, we noticed that the WSGI process pool on the servers was fully saturated. There were were 24 slots/processes per server allocated to process Mercurial requests and all 24 of them were actively processing requests. This created a backlog of requests that had been accepted by the HTTP server but were waiting an internal dispatch/proxy to WSGI. To the client, this would appear as a request with a long lag before response generation.
Mitigation
This being an emergency (trees were already closed and developers were effectively unable to use hg.mozilla.org), we decided to increase the size of the WSGI worker pool. After all, we had CPU, I/O, and memory capacity to spare and we could identify the root cause later. We first bumped worker pool capacity from 24 to 36 and immediately saw a significant reduction in the number of pending requests awaiting a WSGI worker. We still had spare CPU, I/O, and memory capacity and were still seeing requests waiting on a WSGI worker, so we bumped the capacity to 48 processes. At that time, we stopped seeing worker pool exhaustion and all incoming requests were being handed off to a WSGI worker as soon as they came in.
At this time, things were looking pretty healthy from the server end.
Impact on Memory and Swapping
Increasing the number of WSGI processes had the side-effect of increasing the total amount of system memory used by Mercurial processes in two ways. First, more processes means more memory. That part is obvious. Second, more processes means fewer requests for each process per unit of time and thus it takes longer for each process to reach its max number of requests being being reaped. (It is a common practice in servers to have a single process hand multiple requests. This prevents overhead associated with spawning a new process and loading possibly expensive context in it.)
We had our Mercurial WSGI processes configured to serve 100 requests before being reaped. With the doubling of WSGI processes from 24 to 48, those processes were lingering for 2x as long as before. Since the Mercurial processes grow over time (they are aggressive about caching repository data), this was slowly exhausting our memory pool.
It took a few hours, but a few servers started flirting with high swap usage. (We don't expect the servers to swap.) This is how we identified that memory use wasn't sane.
We lowered the maximum requests per process from 100 to 50 to match the ratio increase in the WSGI worker pool.
Mercurial Memory "Leak"
When we started looking at the memory usage of WSGI processes in more detail, we noticed something strange: RSS of Mercurial processes was growing steadily when processes were streaming bundle data. This seemed very odd to me. Being a Mercurial developer, I was pretty sure the behavior was wrong.
I filed a bug against Mercurial.
I was able to reproduce the issue locally and started running a bisection to find the regressing changeset. To my surprise, this issue has been around since Mercurial 2.7!
I looked at the code in question, identified why so much memory was being allocated, and submitted patches to stop an unbounded memory growth during clone/pull and to further reduce memory use during those operations. Both of those patches have been queued to go in the next stable release of Mercurial, 3.2.1.
Mercurial 3.2 is still not as memory efficient during clones as Mercurial 2.5.4. If I have time, I'd like to formulate more patches. But the important fix - not growing memory unbounded during clone/pull - is in place.
Armed with the knowledge that Mercurial is leaky (although not a leak in the traditional sense since the memory was eventually getting garbage collected), we further reduced the max requests per process from 50 to 20. This will cause processes to get reaped sooner and will be more aggressive about keeping RSS growth in check.
Root Cause
We suspect the root cause of the event is a network event.
Before this outage, we rarely had more than 10 requests being served from the WSGI worker pool. In other words, we were often well below 50% capacity. But something changed yesterday. More slots were being occupied and high-bandwidth operations were taking longer to complete. Kendall Libby noted that outbound traffic dropped by ~800 Mbps during the event. For reasons that still haven't been identified, the network became slower, clones weren't being processed as quickly, and clients were occupying WSGI processes for longer amounts of time. This eventually exhausted the available process pool, leading to HTTP 503's, intermittent service availability, and a tree closure.
Interestingly, we noticed that in-flight HTTP requests are abnormally high again this morning. However, because the servers are now configured to handle the extra capacity, we seem to be powering through it without any issues.
In Hindsight
You can make the argument that the servers weren't configured to serve as much traffic as possible. After all, we were able to double the WSGI process pool without hitting CPU, I/O, and memory limits.
The servers were conservatively configured. However, the worker pool was initially configured at 2x CPU core count. And as a general rule of thumb, you don't want your worker pool to be much greater than CPU count because that introduces context switching and can give each individual process a smaller slice of the CPU to process requests, leading to higher latency. Since clone operations often manage to peg a single CPU core, there is some justification for keeping the ratio of WSGI workers to CPU count low. Furthermore, we rarely came close to exhausting the WSGI worker pool before. There was little to no justification for increasing capacity to a threshold not normally seen.
But at the same time, even with 4x workers to CPU cores, our CPU usage rarely flirts with 100% across all cores, even with the majority of workers occupied. Until we actually hit CPU (or I/O) limits, running a high multiplier seems like the right thing to do.
Long term, we expect CPU usage during clone operations to drop dramatically. Mike Hommey has contributed a patch to Mercurial that allows servers to hand out a URL of a bundle file to fetch during clone. So, a server can say I have your data: fetch this static file from S3 and then apply this small subset of the data that I'll give you. When properly deployed and used at Mozilla, this will effectively drop server-side CPU usage for clones to nothing.
Where to do Better
There was a long delay between the Nagios alerts firing and someone with domain-specific knowledge looking at the problem.
The trees could have reopened earlier. We were pretty confident about the state of things at 1000. Trees opened in metered mode at 1246 and completely at 1909. Although, the swapping issue wasn't mitigated until 1615, so you can argue that being conservative on the tree reopening was justified. There is a chance that full reopening could have triggered excessive swap and another round of chaos for everyone involved.
We need an alert on WSGI pool exhaustion. It took longer than it should have to identify this problem. However, now that we've encountered it, it should be obvious if/when it happens again.
Firefox release automation is the largest single consumer of hg.mozilla.org. Since they are operating thousands of machines, any reduction in interaction or increase in efficiency will result in drastic load reductions on the server. Chris AtLee and Jordan Lund have been working on bug 1050109 to reduce clones of the mozharness and build/tools repositories, which should go a long way to dropping load on the server.
Timeline of Events
All times PST.
November 6
- 0705 - First Nagios alerts fire
- 0819 - Trees closed
- 0915 - WSGI process pool increased from 24 to 36
- 0945 - WSGI process pool increased from 36 to 48
- 1246 - Trees reopen in metered mode
- 1615 - Decrease max requests per process from 100 to 50
- 1909 - Trees open completely
November 7
- 0012 - Patches to reduce memory usage submitted to Mercurial
- 0800 - Mercurial patches accepted
- 0915 - Decrease max requests per process from 50 to 20
Soft Launch of MozReview
October 30, 2014 at 11:15 AM | categories: MozReview, Mozilla, code reviewWe performed a soft launch of MozReview: Mozilla's new code review tool yesterday!
What does that mean? How do I use it? What are the features? How do I get in touch or contribute? These are all great questions. The answers to those and more can all be found in the MozReview documentation. If they aren't, it's a bug in the documentation. File a bug or submit a patch. Instructions to do that are in the documentation.
« Previous Page -- Next Page »