Revisiting Using Docker
May 16, 2018 at 01:45 PM | categories: Docker, MozillaWhen Docker was taking off like wildfire in 2013, I was caught up in the excitement like everyone else. I remember knowing of the existence of LXC and container technologies in Linux at the time. But Docker seemed to be the first open source tool to actually make that technology usable (a terrific example of how user experience matters).
At Mozilla, Docker was adopted all around me and by me for various utilities. Taskcluster - Mozilla's task execution framework geared for running complex CI systems - adopted Docker as a mechanism to run processes in self-contained images. Various groups in Mozilla adopted Docker for running services in production. I adopted Docker for integration testing of complex systems.
Having seen various groups use Docker and having spent a lot of time in the trenches battling technical problems, my conclusion is Docker is unsuitable as a general purpose container runtime. Instead, Docker has its niche for hosting complex network services. Other uses of Docker should be highly scrutinized and potentially discouraged.
When Docker hit first the market, it was arguably the only game in town. Using Docker to achieve containerization was defensible because there weren't exactly many (any?) practical alternatives. So if you wanted to use containers, you used Docker.
Fast forward a few years. We now have the Open Container Initiative (OCI). There are specifications describing common container formats. So you can produce a container once and take it to any number OCI compatible container runtimes for execution. And in 2018, there are a ton of players in this space. runc, rkt, and gVisor are just some. So Docker is no longer the only viable tool for executing a container. If you are just getting started with the container space, you would be wise to research the available options and their pros and cons.
When you look at all the options for running containers in 2018, I think it is obvious that Docker - usable though it may be - is not ideal for a significant number of container use cases. If you divide use cases into a spectrum where one end is run a process in a sandbox and the other is run a complex system of orchestrated services in production, Docker appears to be focusing on the latter. Take it from Docker themselves:
Docker is the company driving the container movement and the only container platform provider to address every application across the hybrid cloud. Today's businesses are under pressure to digitally transform but are constrained by existing applications and infrastructure while rationalizing an increasingly diverse portfolio of clouds, datacenters and application architectures. Docker enables true independence between applications and infrastructure and developers and IT ops to unlock their potential and creates a model for better collaboration and innovation.
That description of Docker (the company) does a pretty good job of describing what Docker (the technology) has become: a constellation of software components providing the underbelly for managing complex applications in complex infrastructures. That's pretty far detached on the spectrum from run a process in a sandbox.
Just because Docker (the company) is focused on a complex space doesn't mean they are incapable of exceeding at solving simple problems. However, I believe that in this particular case, the complexity of what Docker (the company) is focusing on has inhibited its Docker products to adequately address simple problems.
Let's dive into some technical specifics.
At its most primitive, Docker is a glorified tool to run a process in a sandbox. On Linux, this is accomplished by using the clone(2) function with specific flags and combined with various other techniques (filesystem remounting, capabilities, cgroups, chroot, seccomp, etc) to sandbox the process from the main operating system environment and kernel. There are a host of tools living at this not-quite-containers level that make it easy to run a sandboxed process. The bubblewrap tool is one of them.
Strictly speaking, you don't need anything fancy to create a process sandbox: just an executable you want to invoke and an executable that makes a set of system calls (like bubblewrap) to run that executable.
When you install Docker on a machine, it starts a daemon running as root.
That daemon listens for HTTP requests on a network port and/or UNIX socket.
When you run docker run from the command line, that command establishes
a connection to the Docker daemon and sends any number of HTTP requests to
instruct the daemon to take actions.
A daemon with a remote control protocol is useful. But it shouldn't be the only way to spawn containers with Docker. If all I want to do is spawn a temporary container that is destroyed afterwards, I should be able to do that from a local command without touching a network service. Something like bubblewrap. The daemon adds all kinds of complexity and overhead. Especially if I just want to run a simple, short-lived command.
Docker at this point is already pretty far detached from a tool like bubblewrap. And the disparity gets worse.
Docker adds another abstraction on top of basic process sandboxing in the form of storage / filesystem management. Docker insists that processes execute in self-contained, chroot()'d filesystem environment and that these environments (Docker images) be managed by Docker itself. When Docker images are imported into Docker, Docker manages them using one of a handful of storage drivers. You can choose from devicemapper, overlayfs, zfs, btrfs, and aufs and employ various configurations of all these. Docker images are composed of layers, with one layer stacked on top of the prior. This allows you to have an immutable base layer (that can be shared across containers) where run-time file changes can be isolated to a specific container instance.
Docker's ability to manage storage is pretty cool. And I dare say Docker's killer feature in the very beginning of Docker was the ability to easily produce and exchange self-contained Docker images across machines.
But this utility comes at a very steep price. Again, if our use case is run a process in a sandbox, do we really care about all this advanced storage functionality? Yes, if you are running hundreds of containers on a single system, a storage model built on top of copy-on-write is perhaps necessary for scaling. But for simple cases where you just want to run a single or small number of processes, it is extremely overkill and adds many more problems than it solves.
I cannot stress this enough, but I have spent hours debugging and working around problems due to how filesystems/storage works in Docker.
When Docker was initially released, aufs was widely used. As I previously wrote, aufs has abysmal performance as you scale up the number of concurrent I/O operations. We shaved minutes off tasks in Firefox CI by ditching aufs for overlayfs.
But overlayfs is far from a panacea. File metadata-only updates are
apparently very slow in overlayfs.
We're talking ~100ms to call fchownat() or utimensat(). If you perform
an rsync -a or chown -R on a directory with only just a hundred files that
were defined in a base image layer, you can have delays of seconds.
The Docker storage drivers backed by real filesystems like zfs and btrfs are a bit better. But they have their quirks too. For example, creating layers in images is comparatively very slow compared to overlayfs (which are practically instantaneous). This matters when you are iterating on a Dockerfile for example and want to quickly test changes. Your edit-compile cycle grows frustratingly long very quickly.
And I could opine on a handful of other problems I've encountered over the years.
Having spent hours of my life debugging and working around issues with Docker's storage, my current attitude is enough of this complexity, just let me use a directory backed by the local filesystem, dammit.
For many use cases, you don't need the storage complexity that Docker forces
upon you. Pointing Docker at a directory on a local filesystem to chroot into
is good enough. I know the behavior and performance properties of common Linux
filesystems. ext4 isn't going to start making fchownat() or utimensat() calls
take ~100ms. It isn't going to complain when a hard link spans multiple layers in
an image. Or slow down to a crawl when multiple threads are performing concurrent
read I/O. There's not going to be intrinsically complicated algorithms and
caching to walk N image layers to find the most recent version of a file (or if
there is, it will be so far down the stack in kernel land that I likely won't
ever have to deal with it as a normal user). Docker images with their multiple
layers add complexity and overhead. For many use uses, the pain it inflicts
offsets the initial convenience it saves.
Docker's optimized-for-complex-use-cases architecture demonstrates its inefficiency in simple benchmarks.
On my machine, docker run -i --rm debian:stretch /bin/ls / takes ~850ms.
Almost a second to perform a directory listing (sometimes it does take over
1 second - I was being generous and quoting a quicker time). This command
takes ~1ms when run in a local shell. So we're at 2.5-3 magnitudes of overhead.
The time here does include time to initially create the container and
destroy it afterwards. We can isolate that overhead by starting a persistent
container and running docker exec -i <cid> /bin/ls / to spawn a new process
in an existing container. This takes ~85ms. So, ~2 magnitudes of overhead to
spawn a process in a Docker container versus spawning it natively. What's
adding so much overhead, I'm not sure. Yes, there are HTTP requests under
the hood. But HTTP to a local daemon shouldn't be that slow. I'm not sure
what's going on.
If we docker export that image to the local filesystem and use runc state
to configure so we can run it with runc, runc run takes ~85ms to run
/bin/ls /. If we runc exec <cid> /bin/ls / to start a process in an
existing container, that completes in ~10ms. runc appears to be executing
these simple tasks ~10x faster than Docker.
But to even get to that point, we had to make a filesystem available to
spawn the container in. With Docker, you need to load an image into Docker.
Using docker save to produce a 105,523,712 tar file,
docker load -i image.tar takes ~1200ms to complete. tar xf image.tar
takes ~65ms to extract that image to the local filesystem. Granted, Docker
is computing the SHA-256 of the image as part of import. But SHA-256 runs
at ~250MB/s on my machine and on that ~105MB input takes ~400ms. Where is
that extra ~750ms of overhead in Docker coming from?
The Docker image loading overhead is still present on large images. With
a 4,336,605,184 image, docker load was taking ~32s and tar x was
taking ~2s. Obviously the filesystem was buffering writes in the tar
case. And the ~2s is ignoring the ~17s to obtain the SHA-256 of the
entire input. But there's still a substantial disparity here. (I suspect
a lot of it is overlayfs not being as optimal as ext4.)
Several years ago there weren't many good choices for tools to execute containers.
But today, there are good tools readily available. And thanks to OCI standards,
you can often swap in alternate container runtimes. Docker (the tool) has an
architecture that is optimized for solving complex use cases (coincidentally use
cases that Docker the company makes money from). Because of this, my conclusion -
drawn from using Docker for several years - is that Docker is unsuitable for
many common use cases. If you care about low container startup/teardown
overhead, low latency when interacting with containers (including spawning
processes from outside of them), and for workloads where Docker's storage model
interferes with understanding or performance, I think Docker should be avoided.
A simpler tool (such as runc or even bubblewrap) should be used instead.
Call me a curmudgeon, but having seen all the problems that Docker's complexity causes, I'd rather see my containers resemble a tarball that can easily be chroot()'d into. I will likely be revisiting projects that use Docker and replacing Docker with something lighter weight and architecturally simpler. As for the use of Docker in the more complex environments it seems to be designed for, I don't have a meaningful opinion as I've never really used it in that capacity. But given my negative experiences with Docker over the years, I am definitely biased against Docker and will lean towards simpler products, especially if their storage/filesystem management model is simpler. Docker introduced containers to the masses and they should be commended for that. But for my day-to-day use cases for containers, Docker is simply not the right tool for the job.
I'm not sure exactly what I'll replace Docker with for my simpler use cases. If you have experiences you'd like to share, sharing them in the comments will be greatly appreciated.
Release of python-zstandard 0.9
April 09, 2018 at 09:30 AM | categories: Python, MozillaI have just released
python-zstandard 0.9.0. You can
install the latest release by running pip install zstandard==0.9.0.
Zstandard is a highly tunable and therefore flexible compression algorithm with support for modern features such as multi-threaded compression and dictionaries. Its performance is remarkable and if you use it as a drop-in replacement for zlib, bzip2, or other common algorithms, you'll frequently see more than a doubling in performance.
python-zstandard provides rich bindings to the zstandard C library without sacrificing performance, safety, features, or a Pythonic feel. The bindings run on Python 2.7, 3.4, 3.5, 3.6, 3.7 using either a C extension or CFFI bindings, so it works with CPython and PyPy.
I can make a compelling argument that python-zstandard is one of the richest compression packages available to Python programmers. Using it, you will be able to leverage compression in ways you couldn't with other packages (especially those in the standard library) all while achieving ridiculous performance. Due to my focus on performance, python-zstandard is able to outperform Python bindings to other compression libraries that should be faster. This is because python-zstandard is very diligent about minimizing memory allocations and copying, minimizing Python object creation, reusing state, etc.
While python-zstandard is formally marked as a beta-level project and hasn't yet reached a 1.0 release, it is suitable for production usage. python-zstandard 0.8 shipped with Mercurial and is in active production use there. I'm also aware of other consumers using it in production, including at Facebook and Mozilla.
The sections below document some of the new features of python-zstandard 0.9.
File Object Interface for Reading
The 0.9 release contains a stream_reader() API on the compressor and
decompressor objects that allows you to treat those objects as readable file
objects. This means that you can pass a ZstdCompressor or ZstdDecompressor
around to things that accept file objects and things generally just work.
e.g.:
with open(compressed_file, 'rb') as ifh: cctx = zstd.ZstdDecompressor() with cctx.stream_reader(ifh) as reader: while True: chunk = reader.read(32768) if not chunk: break
This is probably the most requested python-zstandard feature.
While the feature is usable, it isn't complete. Support for readline(),
readinto(), and a few other APIs is not yet implemented. In addition,
you can't use these reader objects for opening zstandard compressed
tarball files because Python's tarfile package insists on doing
backward seeks when reading. The current implementation doesn't support
backwards seeking because that requires buffering decompressed output and that
is not trivial to implement. I recognize that all these features are useful
and I will try to work them into a subsequent release of 0.9.
Negative Compression Levels
The 1.3.4 release of zstandard (which python-zstandard 0.9 bundles) supports negative compression levels. I won't go into details, but negative compression levels disable extra compression features and allow you to trade compression ratio for more speed.
When compressing a 6,472,921,921 byte uncompressed bundle of the Firefox Mercurial repository, the previous fastest we could go with level 1 was ~510 MB/s (measured on the input side) yielding a 1,675,227,803 file (25.88% of original).
With level -1, we compress to 1,934,253,955 (29.88% of original) at
~590 MB/s. With level -5, we compress to 2,339,110,873 bytes (36.14% of
original) at ~720 MB/s.
On the decompress side, level 1 decompresses at ~1,150 MB/s (measured at the output side), -1 at ~1,320 MB/s, and -5 at ~1,350 MB/s (generally speaking, zstandard's decompression speeds are relatively similar - and fast - across compression levels).
And that's just with a single thread. zstandard supports using multiple threads to compress a single input and python-zstandard makes this feature easy to use. Using 8 threads on my 4+4 core i7-6700K, level 1 compresses at ~2,000 MB/s (3.9x speedup), -1 at ~2,300 MB/s (3.9x speedup), and -5 at ~2,700 MB/s (3.75x speedup).
That's with a large input. What about small inputs?
If we take 456,599 Mercurial commit objects spanning 298,609,254 bytes from the Firefox repository and compress them individually, at level 1 we yield a total of 133,457,198 bytes (44.7% of original) at ~112 MB/s. At level -1, we compress to 161,241,797 bytes (54.0% of original) at ~215 MB/s. And at level -5, we compress to 185,885,545 bytes (62.3% of original) at ~395 MB/s.
On the decompression side, level 1 decompresses at ~260 MB/s, -1 at ~1,000 MB/s, and -5 at ~1,150 MB/s.
Again, that's 456,599 operations on a single thread with Python.
python-zstandard has an experimental API where you can pass in a collection of inputs and it batch compresses or decompresses them in a single operation. It releases and GIL and uses multiple threads. It puts the results in shared buffers in order to minimize the overhead of memory allocations and Python object creation and garbage collection. Using this mode with 8 threads on my 4+4 core i7-6700K, level 1 compresses at ~525 MB/s, -1 at ~1,070 MB/s, and -5 at ~1,930 MB/s. On the decompression side, level 1 is ~1,320 MB/s, -1 at ~3,800 MB/s, and -5 at ~4,430 MB/s.
So, my consumer grade desktop i7-6700K is capable of emitting decompressed
data at over 4 GB/s with Python. That's pretty good if you ask me. (Full
disclosure: the timings were taken just around the compression operation
itself: overhead of loading data into memory was not taken into account. See
the bench.py script in the
source repository for more.
Long Distance Matching Mode
Negative compression levels take zstandard into performance territory that has historically been reserved for compression formats like lz4 that are optimized for that domain. Long distance matching takes zstandard in the other direction, towards compression formats that aim to achieve optimal compression ratios at the expense of time and memory usage.
python-zstandard 0.9 supports long distance matching and all the configurable parameters exposed by the zstandard API.
I'm not going to capture many performance numbers here because python-zstandard performs about the same as the C implementation because LDM mode spends most of its time in zstandard C code. If you are interested in numbers, I recommend reading the zstandard 1.3.2 and 1.3.4 release notes.
I will, however, underscore that zstandard can achieve close to lzma's
compression ratios (what the xz utility uses) while completely smoking
lzma on decompression speed. For a bundle of the Firefox Mercurial repository,
zstandard level 19 with a long distance window size of 512 MB using 8 threads
compresses to 1,033,633,309 bytes (16.0%) in ~260s wall, 1,730s CPU.
xz -T8 -8 compresses to 1,009,233,160 (15.6%) in ~367s wall, ~2,790s CPU.
On the decompression side, zstandard takes ~4.8s and runs at ~1,350 MB/s as
measured on the output side while xz takes ~54s and runs at ~114 MB/s.
Zstandard, however, does use a lot more memory than xz for decompression,
so that performance comes with a cost (512 MB versus 32 MB for this
configuration).
Other Notable Changes
python-zstandard now uses the advanced compression and decompression APIs everywhere. All tunable compression and decompression parameters are available to python-zstandard. This includes support for disabling magic headers in frames (saves 4 bytes per frame - this can matter for very small inputs, especially when using dictionary compression).
The full dictionary training API is exposed. Dictionary training can now use multiple threads.
There are a handful of utility functions for inspecting zstandard frames, querying the state of compressors, etc.
Lots of work has gone into shoring up the code base. We now build with warnings as errors in CI. I performed a number of focused auditing passes to fix various classes of deficiencies in the C code. This includes use of the buffer protocol: python-zstandard is now able to accept any Python object that provides a view into its underlying raw data.
Decompression contexts can now be constructed with a max memory threshold so attempts to decompress something that would require more memory will result in error.
See the full release notes for more.
Conclusion
Since I last released a major version of python-zstandard, a lot has changed in the zstandard world. As I blogged last year, zstandard circa early 2017 was a very compelling compression format: it already outperformed popular compression formats like zlib and bzip2 across the board. As a general purpose compression format, it made a compelling case for itself. In my mind, brotli was its only real challenger.
As I wrote then, zstandard isn't perfect. (Nothing is.) But a year later, it is refreshing to see advancements.
A criticism one year ago was zstandard was pretty good as a general purpose compression format but it wasn't great if you live at the fringes. If you were a speed freak, you'd probably use lz4. If you cared about compression ratios, you'd probably use lzma. But recent releases of zstandard have made huge strides into the territory of these niche formats. Negative compression levels allow zstandard to flirt with lz4's performance. Long distance matching allows zstandard to achieve close to lzma's compression ratios. This is a big friggin deal because it makes it much, much harder to justify a domain-specific compression format over zstandard. I think lzma still has a significant edge for ultra compression ratios when memory utilization is a concern. But for many consumers, memory is readily available and it is easy to justify trading potentially hundreds of megabytes of memory to achieve a 10x speedup for decompression. Even if you aren't willing to sacrifice more memory, the ability to tweak compression parameters is huge. You can do things like store multiple versions of a compressed document and conditionally serve the one most appropriate for the client, all while running the same zstandard-only code on the client. That's huge.
A year later, zstandard continues to impress me for its set of features and its versatility. The library is continuing to evolve - all while maintaining backwards compatibility on the decoding side. (That's a sign of a good format design if you ask me.) I was honestly shocked to see that zstandard was able to change its compression settings in a way that allowed it to compete with lz4 and lzma without requiring a format change.
The more I use zstandard, the more I think that everyone should use this and that popular compression formats just aren't cut out for modern computing any more. Every time I download a zlib/gz or bzip2 compressed archive, I'm thinking if only they used zstandard this archive would be smaller, it would have decompressed already, and I wouldn't be thinking about how annoying it is to wait for compression operations to complete. In my mind, zstandard is such an obvious advancement over the status quo and is such a versatile format - now covering the gamut of super fast compression to ultra ratios - that it is bordering on negligent to not use zstandard. With the removal of the controversial patent rights grant license clause in zstandard 1.3.1, that justifiable resistance to widespread adoption of zstandard has been eliminated. Zstandard is objectively superior for many workloads and I heavily encourage its use. I believe python-zstandard provides a high-quality interface to zstandard and I encourage you to give it and zstandard a try the next time you compress data.
If you run into any problems or want to get involved with development, python-zstandard lives at indygreg/python-zstandard on GitHub.
*(I updated the post on 2018-05-16 to remove a paragraph about zstandard competition. In the original post, I unfairly compared zstandard to Snappy instead of Brotli and made some inaccurate statements around that comparison.)
High-level Problems with Git and How to Fix Them
December 11, 2017 at 10:30 AM | categories: Git, Mercurial, MozillaI have a... complicated relationship with Git.
When Git first came onto the scene in the mid 2000's, I was initially skeptical because of its horrible user interface. But once I learned it, I appreciated its speed and features - especially the ease at which you could create feature branches, merge, and even create commits offline (which was a big deal in the era when Subversion was the dominant version control tool in open source and you needed to speak with a server in order to commit code). When I started using Git day-to-day, it was such an obvious improvement over what I was using before (mainly Subversion and even CVS).
When I started working for Mozilla in 2011, I was exposed to the Mercurial version control, which then - and still today - hosts the canonical repository for Firefox. I didn't like Mercurial initially. Actually, I despised it. I thought it was slow and its features lacking. And I frequently encountered repository corruption.
My first experience learning the internals of both Git and Mercurial came when I found myself hacking on hg-git - a tool that allows you to convert Git and Mercurial repositories to/from each other. I was hacking on hg-git so I could improve the performance of converting Mercurial repositories to Git repositories. And I was doing that because I wanted to use Git - not Mercurial - to hack on Firefox. I was trying to enable an unofficial Git mirror of the Firefox repository to synchronize faster so it would be more usable. The ulterior motive was to demonstrate that Git is a superior version control tool and that Firefox should switch its canonical version control tool from Mercurial to Git.
In what is a textbook definition of irony, what happened instead was I actually learned how Mercurial worked, interacted with the Mercurial Community, realized that Mozilla's documentation and developer practices were... lacking, and that Mercurial was actually a much, much more pleasant tool to use than Git. It's an old post, but I summarized my conversion four and a half years ago. This started a chain of events that somehow resulted in me contributing a ton of patches to Mercurial, taking stewardship of hg.mozilla.org, and becoming a member of the Mercurial Steering Committee - the governance group for the Mercurial Project.
I've been an advocate of Mercurial over the years. Some would probably say I'm a Mercurial fanboy. I reject that characterization because fanboy has connotations that imply I'm ignorant of realities. I'm well aware of Mercurial's faults and weaknesses. I'm well aware of Mercurial's relative lack of popularity, I'm well aware that this lack of popularity almost certainly turns away contributors to Firefox and other Mozilla projects because people don't want to have to learn a new tool. I'm well aware that there are changes underway to enable Git to scale to very large repositories and that these changes could threaten Mercurial's scalability advantages over Git, making choices to use Mercurial even harder to defend. (As an aside, the party most responsible for pushing Git to adopt architectural changes to enable it to scale these days is Microsoft. Could anyone have foreseen that?!)
I've achieved mastery in both Git and Mercurial. I know their internals and their command line interfaces extremely well. I understand the architecture and principles upon which both are built. I'm also exposed to some very experienced and knowledgeable people in the Mercurial Community. People who have been around version control for much, much longer than me and have knowledge of random version control tools you've probably never heard of. This knowledge and exposure allows me to make connections and see opportunities for version control that quite frankly most do not.
In this post, I'll be talking about some high-level, high-impact problems with Git and possible solutions for them. My primary goal of this post is to foster positive change in Git and the services around it. While I personally prefer Mercurial, improving Git is good for everyone. Put another way, I want my knowledge and perspective from being part of a version control community to be put to good wherever it can.
Speaking of Mercurial, as I said, I'm a heavy contributor and am somewhat influential in the Mercurial Community. I want to be clear that my opinions in this post are my own and I'm not speaking on behalf of the Mercurial Project or the larger Mercurial Community. I also don't intend to claim that Mercurial is holier-than-thou. Mercurial has tons of user interface failings and deficiencies. And I'll even admit to being frustrated that some systemic failings in Mercurial have gone unaddressed for as long as they have. But that's for another post. This post is about Git. Let's get started.
The Staging Area
The staging area is a feature that should not be enabled in the default Git configuration.
Most people see version control as an obstacle standing in the way of accomplishing some other task. They just want to save their progress towards some goal. In other words, they want version control to be a save file feature in their workflow.
Unfortunately, modern version control tools don't work that way. For starters, they require people to specify a commit message every time they save. This in of itself can be annoying. But we generally accept that as the price you pay for version control: that commit message has value to others (or even your future self). So you must record it.
Most people want the barrier to saving changes to be effortless. A commit message is already too annoying for many users! The Git staging area establishes a higher barrier to saving. Instead of just saving your changes, you must first stage your changes to be saved.
If you requested save in your favorite GUI application, text editor, etc and it popped open a select the changes you would like to save dialog, you would rightly think just save all my changes already, dammit. But this is exactly what Git does with its staging area! Git is saying I know all the changes you made: now tell me which changes you'd like to save. To the average user, this is infuriating because it works in contrast to how the save feature works in almost every other application.
There is a counterargument to be made here. You could say that the editor/application/etc is complex - that it has multiple contexts (files) - that each context is independent - and that the user should have full control over which contexts (files) - and even changes within those contexts - to save. I agree: this is a compelling feature. However, it isn't an appropriate default feature. The ability to pick which changes to save is a power-user feature. Most users just want to save all the changes all the time. So that should be the default behavior. And the Git staging area should be an opt-in feature.
If intrinsic workflow warts aren't enough, the Git staging area has a
horrible user interface. It is often referred to as the cache
for historical reasons.
Cache of course means something to anyone who knows anything about
computers or programming. And Git's use of cache doesn't at all align
with that common definition. Yet the the terminology in Git persists.
You have to run commands like git diff --cached to examine the state
of the staging area. Huh?!
But Git also refers to the staging area as the index. And this
terminology also appears in Git commands! git help commit has numerous
references to the index. Let's see what git help glossary has to say::
index
A collection of files with stat information, whose contents are
stored as objects. The index is a stored version of your working tree.
Truth be told, it can also contain a second, and even a third
version of a working tree, which are used when merging.
index entry
The information regarding a particular file, stored in the index.
An index entry can be unmerged, if a merge was started, but not
yet finished (i.e. if the index contains multiple versions of that
file).
In terms of end-user documentation, this is a train wreck. It tells the
lay user absolutely nothing about what the index actually is. Instead,
it casually throws out references to stat information (requires the user
know what the stat() function call and struct are) and objects (a Git
term for a piece of data stored by Git). It even undermines its own credibility
with that truth be told sentence. This definition is so bad that it
would probably improve user understanding if it were deleted!
Of course, git help index says No manual entry for gitindex. So
there is literally no hope for you to get a concise, understandable
definition of the index. Instead, it is one of those concepts that you
think you learn from interacting with it all the time. Oh, when I
git add something it gets into this state where git commit will
actually save it.
And even if you know what the Git staging area/index/cached is, it can
still confound you. Do you know the interaction between uncommitted
changes in the staging area and working directory when you git rebase?
What about git checkout? What about the various git reset invocations?
I have a confession: I can't remember all the edge cases either. To play
it safe, I try to make sure all my outstanding changes are committed
before I run something like git rebase because I know that will be
safe.
The Git staging area doesn't have to be this complicated. A re-branding
away from index to staging area would go a long way. Adding an alias
from git diff --staged to git diff --cached and removing references
to the cache from common user commands would make a lot of sense and
reduce end-user confusion.
Of course, the Git staging area doesn't really need to exist at all!
The staging area is essentially a soft commit. It performs the
save progress role - the basic requirement of a version control tool.
And in some aspects it is actually a better save progress implementation
than a commit because it doesn't require you to type a commit message!
Because the staging area is a soft commit, all workflows using it can
be modeled as if it were a real commit and the staging area didn't
exist at all! For example, instead of git add --interactive +
git commit, you can run git commit --interactive. Or if you wish
to incrementally add new changes to an in-progress commit, you can
run git commit --amend or git commit --amend --interactive or
git commit --amend --all. If you actually understand the various modes
of git reset, you can use those to uncommit. Of course, the user
interface to performing these actions in Git today is a bit convoluted.
But if the staging area didn't exist, new high-level commands like
git amend and git uncommit could certainly be invented.
To the average user, the staging area is a complicated concept. I'm a power user. I understand its purpose and how to harness its power. Yet when I use Mercurial (which doesn't have a staging area), I don't miss the staging area at all. Instead, I learn that all operations involving the staging area can be modeled as other fundamental primitives (like commit amend) that you are likely to encounter anyway. The staging area therefore constitutes an unnecessary burden and cognitive load on users. While powerful, its complexity and incurred confusion does not justify its existence in the default Git configuration. The staging area is a power-user feature and should be opt-in by default.
Branches and Remotes Management is Complex and Time-Consuming
When I first used Git (coming from CVS and Subversion), I thought branches and remotes were incredible because they enabled new workflows that allowed you to easily track multiple lines of work across many repositories. And ~10 years later, I still believe the workflows they enable are important. However, having amassed a broader perspective, I also believe their implementation is poor and this unnecessarily confuses many users and wastes the time of all users.
My initial zen moment with Git - the time when Git finally clicked for me -
was when I understood Git's object model: that Git is just a
content indexed key-value store consisting of a different object types
(blobs, trees, and commits) that have a particular relationship with
each other. Refs are symbolic names pointing to Git commit objects. And
Git branches - both local and remote - are just refs having a
well-defined naming convention (refs/heads/<name> for local branches and
refs/remotes/<remote>/<name> for remote branches). Even tags and
notes are defined via refs.
Refs are a necessary primitive in Git because the Git storage model is to throw all objects into a single, key-value namespace. Since the store is content indexed and the key name is a cryptographic hash of the object's content (which for all intents and purposes is random gibberish to end-users), the Git store by itself is unable to locate objects. If all you had was the key-value store and you wanted to find all commits, you would need to walk every object in the store and read it to see if it is a commit object. You'd then need to buffer metadata about those objects in memory so you could reassemble them into say a DAG to facilitate looking at commit history. This approach obviously doesn't scale. Refs short-circuit this process by providing pointers to objects of importance. It may help to think of the set of refs as an index into the Git store.
Refs also serve another role: as guards against garbage collection. I won't go into details about loose objects and packfiles, but it's worth noting that Git's key-value store also behaves in ways similar to a generational garbage collector like you would find in programming languages such as Java and Python. The important thing to know is that Git will garbage collect (read: delete) objects that are unused. And the mechanism it uses to determine which objects are unused is to iterate through refs and walk all transitive references from that initial pointer. If there is an object in the store that can't be traced back to a ref, it is unreachable and can be deleted.
Reflogs maintain the history of a value for a ref: for each ref they contain a log of what commit it was pointing to, when that pointer was established, who established it, etc. Reflogs serve two purposes: facilitating undoing a previous action and holding a reference to old data to prevent it from being garbage collected. The two use cases are related: if you don't care about undo, you don't need the old reference to prevent garbage collection.
This design of Git's store is actually quite sensible. It's not perfect (nothing is). But it is a solid foundation to build a version control tool (or even other data storage applications) on top of.
The title of this section has to do with sub-optimal branches and remotes management. But I've hardly said anything about branches or remotes! And this leads me to my main complaint about Git's branches and remotes: that they are very thin veneer over refs. The properties of Git's underlying key-value store unnecessarily bleed into user-facing concepts (like branches and remotes) and therefore dictate sub-optimal practices. This is what's referred to as a leaky abstraction.
I'll give some examples.
As I stated above, many users treat version control as a save file step in their workflow. I believe that any step that interferes with users saving their work is user hostile. This even includes writing a commit message! I already argued that the staging area significantly interferes with this critical task. Git branches do as well.
If we were designing a version control tool from scratch (or if you were
a new user to version control), you would probably think that a sane
feature/requirement would be to update to any revision and start making
changes. In Git speak, this would be something like
git checkout b201e96f, make some file changes, git commit. I think
that's a pretty basic workflow requirement for a version control tool.
And the workflow I suggested is pretty intuitive: choose the thing to
start working on, make some changes, then save those changes.
Let's see what happens when we actually do this:
$ git checkout b201e96f
Note: checking out 'b201e96f'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at b201e96f94... Merge branch 'rs/config-write-section-fix' into maint
$ echo 'my change' >> README.md
$ git commit -a -m 'my change'
[detached HEAD aeb0c997ff] my change
1 file changed, 1 insertion(+)
$ git push indygreg
fatal: You are not currently on a branch.
To push the history leading to the current (detached HEAD)
state now, use
git push indygreg HEAD:<name-of-remote-branch>
$ git checkout master
Warning: you are leaving 1 commit behind, not connected to
any of your branches:
aeb0c997ff my change
If you want to keep it by creating a new branch, this may be a good time
to do so with:
git branch <new-branch-name> aeb0c997ff
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
I know what all these messages mean because I've mastered Git. But if you were a newcomer (or even a seasoned user), you might be very confused. Just so we're on the same page, here is what's happening (along with some commentary).
When I run git checkout b201e96f, Git is trying to tell me that I'm
potentially doing something that could result in the loss of my data. A
golden rule of version control tools is don't lose the user's data. When
I run git checkout, Git should be stating the risk for data loss very
clearly. But instead, the If you want to create a new branch sentence is
hiding this fact by instead phrasing things around retaining commits you
create rather than the possible loss of data. It's up to the user
to make the connection that retaining commits you create actually means
don't eat my data. Preventing data loss is critical and Git should not
mince words here!
The git commit seems to work like normal. However, since we're in a
detached HEAD state (a phrase that is likely gibberish to most users),
that commit isn't referred to by any ref, so it can be lost easily.
Git should be telling me that I just committed something it may not
be able to find in the future. But it doesn't. Again, Git isn't being
as protective of my data as it needs to be.
The failure in the git push command is essentially telling me I need
to give things a name in order to push. Pushing is effectively remote
save. And I'm going to apply my reasoning about version control tools
not interfering with save to pushing as well: Git is adding an
extra barrier to remote save by refusing to push commits without a
branch attached and by doing so is being user hostile.
Finally, we git checkout master to move to another commit. Here, Git
is actually doing something halfway reasonable. It is telling me I'm
leaving commits behind, which commits those are, and the command to
use to keep those commits. The warning is good but not great. I think
it needs to be stronger to reflect the risk around data loss if that
suggested Git commit isn't executed. (Of course, the reflog for HEAD
will ensure that data isn't immediately deleted. But users shouldn't
need to involve reflogs to not lose data that wasn't rewritten.)
The point I want to make is that Git doesn't allow you to just update and save. Because its dumb store requires pointers to relevant commits (refs) and because that requirement isn't abstracted away or paved over by user-friendly features in the frontend, Git is effectively requiring end-users to define names (branches) for all commits. If you fail to define a name, it gets a lot harder to find your commits, exchange them, and Git may delete your data. While it is technically possible to not create branches, the version control tool is essentially unusable without them.
When local branches are exchanged, they appear as remote branches to others. Essentially, you give each instance of the repository a name (the remote). And branches/refs fetched from a named remote appear as a ref in the ref namespace for that remote. e.g. refs/remotes/origin holds refs for the origin remote. (Git allows you to not have to specify the refs/remotes part, so you can refer to e.g. refs/remotes/origin/master as origin/master.)
Again, if you were designing a version control tool from scratch or you
were a new Git user, you'd probably think remote refs would make
good starting points for work. For example, if you know you should be
saving new work on top of the master branch, you might be inclined
to begin that work by running git checkout origin/master. But like
our specific-commit checkout above:
$ git checkout origin/master
Note: checking out 'origin/master'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 95ec6b1b33... RelNotes: the eighth batch
This is the same message we got for a direct checkout. But we did
supply a ref/remote branch name. What gives? Essentially, Git tries
to enforce that the refs/remotes/ namespace is read-only and only
updated by operations that exchange data with a remote, namely git fetch,
git pull, and git push.
For this to work correctly, you need to create a new local branch
(which initially points to the commit that refs/remotes/origin/master
points to) and then switch/activate that local branch.
I could go on talking about all the subtle nuances of how Git branches are managed. But I won't.
If you've used Git, you know you need to use branches. You may or may
not recognize just how frequently you have to type a branch name into
a git command. I guarantee that if you are familiar with version control
tools and workflows that aren't based on having to manage refs to
track data, you will find Git's forced usage of refs and branches
a bit absurd. I half jokingly refer to Git as Game of Refs. I say that
because coming from Mercurial (which doesn't require you to name things),
Git workflows feel to me like all I'm doing is typing the names of branches
and refs into git commands. I feel like I'm wasting my precious
time telling Git the names of things only because this is necessary to
placate the leaky abstraction of Git's storage layer which requires
references to relevant commits.
Git and version control doesn't have to be this way.
As I said, my Mercurial workflow doesn't rely on naming things. Unlike Git, Mercurial's store has an explicit (not shared) storage location for commits (changesets in Mercurial parlance). And this data structure is ordered, meaning a changeset later always occurs after its parent/predecessor. This means that Mercurial can open a single file/index to quickly find all changesets. Because Mercurial doesn't need pointers to commits of relevance, names aren't required.
My Zen of Mercurial moment came when I realized you didn't have to name things in Mercurial. Having used Git before Mercurial, I was conditioned to always be naming things. This is the Git way after all. And, truth be told, it is common to name things in Mercurial as well. Mercurial's named branches were the way to do feature branches in Mercurial for years. Some used the MQ extension (essentially a port of quilt), which also requires naming individual patches. Git users coming to Mercurial were missing Git branches and Mercurial's bookmarks were a poor port of Git branches.
But recently, more and more Mercurial users have been coming to the realization that names aren't really necessary. If the tool doesn't actually require naming things, why force users to name things? As long as users can find the commits they need to find, do you actually need names?
As a demonstration, my Mercurial workflow leans heavily on the hg show work
and hg show stack commands. You will need to enable the show extension
by putting the following in your hgrc config file to use them:
[extensions]
show =
Running hg show work (I have also set the config
commands.show.aliasprefix=sto enable me to type hg swork) finds all
in-progress changesets and other likely-relevant changesets (those
with names and DAG heads). It prints a concise DAG of those changesets:

And hg show stack shows just the current line of work and its
relationship to other important heads:
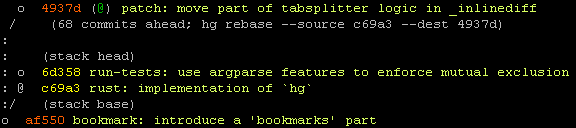
Aside from the @ bookmark/name set on that top-most changeset, there are
no names! (That @ comes from the remote repository, which has set that name.)
Outside of code archeology workflows, hg show work shows the changesets I
care about 95% of the time. With all I care about (my in-progress work and
possible rebase targets) rendered concisely, I don't have to name things
because I can just find whatever I'm looking for by running hg show work!
Yes, you need to run hg show work, visually scan for what you are looking
for, and copy a (random) hash fragment into a number of commands. This
sounds like a lot of work. But I believe it is far less work than naming
things. Only when you practice this workflow do you realize just how much
time you actually spend finding and then typing names in to hg and -
especailly - git commands! The ability to just hg update to a changeset
and commit without having to name things is just so liberating. It feels
like my version control tool is putting up fewer barriers and letting me
work quickly.
Another benefit of hg show work and hg show stack are that they present
a concise DAG visualization to users. This helps educate users about the
underlying shape of repository data. When you see connected nodes on a
graph and how they change over time, it makes it a lot easier to understand
concepts like merge and rebase.
This nameless workflow may sound radical. But that's because we're all
conditioned to naming things. I initially thought it was crazy as well. But
once you have a mechanism that gives you rapid access to data you care
about (hg show work in Mercurial's case), names become very optional. Now,
a pure nameless workflow isn't without its limitations. You want names
to identify the main targets for work (e.g. the master branch). And when
you exchange work with others, names are easier to work with, especially
since names survive rewriting. But in my experience, most of my commits
are only exchanged with me (synchronizing my in-progress commits across
devices) and with code review tools (which don't really need names and
can operate against raw commits). My most frequent use of names comes
when I'm in repository maintainer mode and I need to ensure commits
have names for others to reference.
Could Git support nameless workflows? In theory it can.
Git needs refs to find relevant commits in its store. And the wire protocol uses refs to exchange data. So refs have to exist for Git to function (assuming Git doesn't radically change its storage and exchange mechanisms to mitigate the need for refs, but that would be a massive change and I don't see this happening).
While there is a fundamental requirement for refs to exist, this doesn't necessarily mean that user-facing names must exist. The reason that we need branches today is because branches are little more than a ref with special behavior. It is theoretically possible to invent a mechanism that transparently maps nameless commits onto refs. For example, you could create a refs/nameless/ namespace that was automatically populated with DAG heads that didn't have names attached. And Git could exchange these refs just like it can branches today. It would be a lot of work to think through all the implications and to design and implement support for nameless development in Git. But I think it is possible.
I encourage the Git community to investigate supporting nameless workflows. Having adopted this workflow in Mercurial, Git's workflow around naming branches feels heavyweight and restrictive to me. Put another way, nameless commits are actually lighter-weight branches than Git branches! To the common user who just wants version control to be a save feature, requiring names establishes a barrier towards that goal. So removing the naming requirement would make Git simpler and more approachable to new users.
Forks aren't the Model You are Looking For
This section is more about hosted Git services (like GitHub, Bitbucket, and GitLab) than Git itself. But since hosted Git services are synonymous with Git and interaction with a hosted Git services is a regular part of a common Git user's workflow, I feel like I need to cover it. (For what it's worth, my experience at Mozilla tells me that a large percentage of people who say I prefer Git or we should use Git actually mean I like GitHub. Git and GitHub/Bitbucket/GitLab are effectively the same thing in the minds of many and anyone finding themselves discussing version control needs to keep this in mind because Git is more than just the command line tool: it is an ecosystem.)
I'll come right out and say it: I think forks are a relatively poor model for collaborating. They are light years better than what existed before. But they are still so far from the turn-key experience that should be possible. The fork hasn't really changed much since the current implementation of it was made popular by GitHub many years ago. And I view this as a general failure of hosted services to innovate.
So we have a shared understanding, a fork (as implemented on GitHub,
Bitbucket, GitLab, etc) is essentially a complete copy of a repository
(a git clone if using Git) and a fresh workspace for additional
value-added services the hosting provider offers (pull requests, issues,
wikis, project tracking, release tracking, etc). If you open the main
web page for a fork on these services, it looks just like the main
project's. You know it is a fork because there are cosmetics somewhere
(typically next to the project/repository name) saying forked from.
Before service providers adopted the fork terminology, fork was used in open source to refer to a splintering of a project. If someone or a group of people didn't like the direction a project was taking, wanted to take over ownership of a project because of stagnation, etc, they would fork it. The fork was based on the original (and there may even be active collaboration between the fork and original), but the intent of the fork was to create distance between the original project and its new incantation. A new entity that was sufficiently independent of the original.
Forks on service providers mostly retain this old school fork model. The fork gets a new copy of issues, wikis, etc. And anyone who forks establishes what looks like an independent incantation of a project. It's worth noting that the execution varies by service provider. For example, GitHub won't enable Issues for a fork by default, thereby encouraging people to file issues against the upstream project it was forked from. (This is good default behavior.)
And I know why service providers (initially) implemented things this
way: it was easy. If you are building a product, it's simpler to just
say a user's version of this project is a git clone and they get
a fresh database. On a technical level, this meets the traditional
definition of fork. And rather than introduce a new term into the
vernacular, they just re-purposed fork (albeit with softer
connotations, since the traditional fork commonly implied there
was some form of strife precipitating a fork).
To help differentiate flavors of forks, I'm going to define the terms soft fork and hard fork. A soft fork is a fork that exists for purposes of collaboration. The differentiating feature between a soft fork and hard fork is whether the fork is intended to be used as its own project. If it is, it is a hard fork. If not - if all changes are intended to be merged into the upstream project and be consumed from there - it is a soft fork.
I don't have concrete numbers, but I'm willing to wager that the vast majority of forks on Git service providers which have changes are soft forks rather than hard forks. In other words, these forks exist purely as a conduit to collaborate with the canonical/upstream project (or to facilitate a short-lived one-off change).
The current implementation of fork - which borrows a lot from its predecessor of the same name - is a good - but not great - way to facilitate collaboration. It isn't great because it technically resembles what you'd expect to see for hard fork use cases even though it is used predominantly with soft forks. This mismatch creates problems.
If you were to take a step back and invent your own version control
hosted service and weren't tainted by exposure to existing services
and were willing to think a bit beyond making it a glorified frontend
for the git command line interface, you might realize that the problem
you are solving - the product you are selling - is collaboration as
a service, not a Git hosting service. And if your product is
collaboration, then implementing your collaboration model around the
hard fork model with strong barriers between the original project and
its forks is counterproductive and undermines your own product.
But this is how GitHub, Bitbucket, GitLab, and others have implemented
their product!
To improve collaboration on version control hosted services, the concept of a fork needs to significantly curtailed. Replacing it should be a UI and workflow that revolves around the central, canonical repository.
You shouldn't need to create your own clone or fork of a repository in order to contribute. Instead, you should be able to clone the canonical repository. When you create commits, those commits should be stored and/or more tightly affiliated with the original project - not inside a fork.
One potential implementation is doable today. I'm going to call it workspaces. Here's how it would work.
There would exist a namespace for refs that can be controlled by
the user. For example, on GitHub (where my username is indygreg),
if I wanted to contribute to some random project, I would git push
my refs somewhere under refs/users/indygreg/ directly to that
project's. No forking necessary. If I wanted to contribute to a
project, I would just clone its repo then push to my workspace under
it. You could do this today by configuring your Git refspec properly.
For pushes, it would look something like
refs/heads/*:refs/users/indygreg/* (that tells Git to map local refs
under refs/heads/ to refs/users/indygreg/ on that remote repository).
If this became a popular feature, presumably the Git wire protocol could
be taught to advertise this feature such that Git clients automatically
configured themselves to push to user-specific workspaces attached to
the original repository.
There are several advantages to such a workspace model. Many of them revolve around eliminating forks.
At initial contribution time, no server-side fork is necessary in order to contribute. You would be able to clone and contribute without waiting for or configuring a fork. Or if you can create commits from the web interface, the clone wouldn't even be necessary! Lowering the barrier to contribution is a good thing, especially if collaboration is the product you are selling.
In the web UI, workspaces would also revolve around the source project and not be off in their own world like forks are today. People could more easily see what others are up to. And fetching their work would require typing in their username as opposed to configuring a whole new remote. This would bring communities closer and hopefully lead to better collaboration.
Not requiring forks also eliminates the need to synchronize your fork
with the upstream repository. I don't know about you, but one of the things
that bothers me about the Game of Refs that Git imposes is that I have
to keep my refs in sync with the upstream refs. When I fetch from
origin and pull down a new master branch, I need to git merge
that branch into my local master branch. Then I need to push that new
master branch to my fork. This is quite tedious. And it is easy to merge
the wrong branches and get your branch state out of whack. There are
better ways to map remote refs into your local names to make this far
less confusing.
Another win here is not having to push and store data multiple times.
When working on a fork (which is a separate repository), after you
git fetch changes from upstream, you need to eventually git push those
into your fork. If you've ever worked on a large repository and didn't
have a super fast Internet connection, you may have been stymied by
having to git push large amounts of data to your fork. This is quite
annoying, especially for people with slow Internet connections. Wouldn't
it be nice if that git push only pushed the data that was truly new and
didn't already exist somewhere else on the server? A workspace model
where development all occurs in the original repository would fix this.
As a bonus, it would make the storage problem on servers easier because
you would eliminate thousands of forks and you probably wouldn't have to
care as much about data duplication across repos/clones because the
version control tool solves a lot of this problem for you, courtesy of
having all data live alongside or in the original repository instead of
in a fork.
Another win from workspace-centric development would be the potential to do more user-friendly things after pull/merge requests are incorporated in the official project. For example, the ref in your workspace could be deleted automatically. This would ease the burden on users to clean up after their submissions are accepted. Again, instead of mashing keys to play the Game of Refs, this would all be taken care of for you automatically. (Yes, I know there are scripts and shell aliases to make this more turn-key. But user-friendly behavior shouldn't have to be opt-in: it should be the default.)
But workspaces aren't all rainbows and unicorns. There are access control concerns. You probably don't want users able to mutate the workspaces of other users. Or do you? You can make a compelling case that project administrators should have that ability. And what if someone pushes bad or illegal content to a workspace and you receive a cease and desist? Can you take down just the offending workspace while complying with the order? And what happens if the original project is deleted? Do all its workspaces die with it? These are not trivial concerns. But they don't feel impossible to tackle either.
Workspaces are only one potential alternative to forks. And I can come up with multiple implementations of the workspace concept. Although many of them are constrained by current features in the Git wire protocol. But Git is (finally) getting a more extensible wire protocol, so hopefully this will enable nice things.
I challenge Git service providers like GitHub, Bitbucket, and GitLab to think outside the box and implement something better than how forks are implemented today. It will be a large shift. But I think users will appreciate it in the long run.
Conclusion
Git is an ubiquitous version control tool. But it is frequently lampooned for its poor usability and documentation. We even have research papers telling us which parts are bad. Nobody I know has had a pleasant initial experience with Git. And it is clear that few people actually understand Git: most just know the command incantations they need to know to accomplish a small set of common activities. (If you are such a person, there is nothing to be ashamed about: Git is a hard tool.)
Popular Git-based hosting and collaboration services (such as GitHub,
Bitbucket, and GitLab) exist. While they've made strides to make it
easier to commit data to a Git repository (I purposefully avoid saying
use Git because the most usable tools seem to avoid the git command
line interface as much as possible), they are often a thin veneer over
Git itself (see forks). And Git is a thin veneer over a content
indexed key-value store (see forced usage of bookmarks).
As an industry, we should be concerned about the lousy usability of Git and the tools and services that surround it. Some may say that Git - with its near monopoly over version control mindset - is a success. I have a different view: I think it is a failure that a tool with a user experience this bad has achieved the success it has.
The cost to Git's poor usability can be measured in tens if not hundreds of millions of dollars in time people have wasted because they couldn't figure out how to use Git. Git should be viewed as a source of embarrassment, not a success story.
What's really concerning is that the usability problems of Git have been known for years. Yet it is as popular as ever and there have been few substantial usability improvements. We do have some alternative frontends floating around. But these haven't caught on.
I'm at a loss to understand how an open source tool as popular as Git has remained so mediocre for so long. The source code is out there. Anybody can submit a patch to fix it. Why is it that so many people get tripped up by the same poor usability issues years after Git became the common version control tool? It certainly appears that as an industry we have been unable or unwilling to address systemic deficiencies in a critical tool. Why this is, I'm not sure.
Despite my pessimism about Git's usability and its poor track record of being attentive to the needs of people who aren't power users, I'm optimistic that the future will be brighter. While the ~7000 words in this post pale in comparison to the aggregate word count that has been written about Git, hopefully this post strikes a nerve and causes positive change. Just because one generation has toiled with the usability problems of Git doesn't mean the next generation has to suffer through the same. Git can be improved and I encourage that change to happen. The three issues above and their possible solutions would be a good place to start.
Good Riddance to AUFS
December 08, 2017 at 03:00 PM | categories: Docker, MozillaFor over a year, AUFS - a layering filesystem for Linux - has been giving me fits.
As I initially measured last year, AUFS has... suboptimal performance characteristics. The crux of the problem is that AUFS obtains a global lock in the Linux kernel (at least version 3.13) for various I/O operations, including stat(). If you have more than a couple of active CPU cores, the overhead from excessive kernel locking inside _raw_spin_lock() can add more overhead than extra CPU cores add capacity. That's right: under certain workloads, adding more CPU cores actually slows down execution due to cores being starved waiting for a global lock in the kernel!
If that weren't enough, AUFS can also violate POSIX filesystem guarantees under load. It appears that AUFS sometimes forgets about created files or has race conditions that prevent created files from being visible to readers until many seconds later! I think this issue only occurs when there are concurrent threads creating files.
These two characteristics of AUFS have inflicted a lot of hardship on Firefox's continuous integration. Large parts of Firefox's CI execute in Docker. And the host environment for Docker has historically used Ubuntu 14.04 with Linux 3.13 and Docker using AUFS. AUFS was/is the default storage driver for many versions of Docker. When this storage driver is used, all files inside Docker containers are backed by AUFS unless a Docker volume (a directory bind mounted from the host filesystem - EXT4 in our case) is in play.
When we started using EC2 instances with more CPU cores, we weren't getting a linear speedup for CPU bound operations. Instead, CPU cycles were being spent inside the kernel. Stack profiling showed AUFS as the culprit. We were thus unable to leverage more powerful EC2 instances because adding more cores would only provide marginal to negative gains against significant cost expenditure.
We worked around this problem by making heavy use of Docker volumes for tasks incurring significant I/O. This included version control clones and checkouts.
Somewhere along the line, we discovered that AUFS volumes were also the cause of several random file not found errors throughout automation. Initially, we thought many of these errors were due to bugs in the underlying tools (Mercurial and Firefox's build system were common victims because they do lots of concurrent I/O). When the bugs mysteriously went away after ensuring certain operations were performed on EXT4 volumes, we were able to blame AUFS for the myriad of filesystem consistency problems.
Earlier today, we pushed out a change to upgrade Firefox's CI to Linux 4.4 and switched Docker from AUFS to overlayfs (using the overlay2 storage driver). The improvements exceeded my expectations.
Linux build times have decreased by ~4 minutes, from ~750s to ~510s.
Linux Rust test times have decreased by ~4 minutes, from ~615s to ~380s.
Linux PGO build times have decreased by ~5 minutes, from ~2130s to ~1820s.
And this is just the build side of the world. I don't have numbers off hand, but I suspect many tests also got a nice speedup from this change.
Multiplied by thousands of tasks per day and factoring in the cost to operate these machines, the elimination of AUFS has substantially increased the efficiency (and reliability) of Firefox CI and easily saved Mozilla tens of thousands of dollars per year. And that's just factoring in the savings in the AWS bill. Time is money and people are a lot more expensive than AWS instances (you can run over 3,000 c5.large EC2 instances at spot pricing for what it costs to employ me when I'm on the clock). So the real win here comes from Firefox developers being able to move faster because their builds and tests complete several minutes faster.
In conclusion, if you care about performance or filesystem correctness, avoid AUFS. Use overlayfs instead.
from __past__ import bytes_literals
March 13, 2017 at 09:55 AM | categories: Python, Mercurial, MozillaLast year, I simultaneously committed one of the ugliest and impressive hacks of my programming career. I haven't had time to write about it. Until now.
In summary, the hack is a
source-transforming module loader
for Python. It can be used by Python 3 to import a Python 2 source
file while translating certain primitives to their Python 3 equivalents.
It is kind of like 2to3
except it executes at run-time during import. The main goal of the
hack was to facilitate porting Mercurial to Python 3 while deferring
having to make the most invasive - and therefore most annoying -
elements of the port in the canonical source code representation.
For the technically curious, it works as follows.
The hg Python executable registers a custom
meta path finder
instance. This entity is invoked during import statements to try
to find the module being imported. It tells a later phase of the
import mechanism how to load that module from wherever it is
(usually a .py or .pyc file on disk) to a Python module object.
The custom finder only responds to requests for modules known
to be managed by the Mercurial project. For these modules, it tells
the next stage of the import mechanism to invoke a custom
SourceLoader
instance. Here's where the real magic is: when the custom loader
is invoked, it tokenizes the Python source code using the
tokenize module,
iterates over the token stream, finds specific patterns, and
rewrites them to something more appropriate. It then untokenizes
back to Python source code then falls back to the built-in loader
which does the heavy lifting of compiling the source to Python code
objects. So, we have Python 2 source files on disk that magically get
transformed to be Python compatible when they are loaded by Python 3.
Oh, and there is no performance penalty for the token transformation
on subsequence loads because the transformed bytecode is cached in
the .pyc file (using a custom header so we know it was transformed
and can be invalidated when the transformation logic changes).
At the time I wrote it, the token stream manipulation converted most
string literals ('') to bytes literals (b''). In other words, it
restored the Python 2 behavior of string literals being bytes and
not unicode. We jokingly call it
from __past__ import bytes_literals (a play on Python 2's
from __future__ import unicode_literals special syntax which
changes string literals from Python 2's str/bytes type to
unicode to match Python 3's behavior).
Since I implemented the first version, others have implemented:
- Automatically inserting
a
from mercurial.pycompat import ...statement to the top of the source. This statement is the Mercurial equivalent of importing common wrapper types similar to what six provides. - More robust function argument parsing support. (Because going from a token stream to a higher-level primitive like a function call is difficult.)
- Automatically rewriting
.iteritems()to.items().
As one can expect, when I tweeted a link to this commit, many Python developers (including a few CPython core developers) expressed a mix of intrigue and horror. But mostly horror.
I fully concede that what I did here is a gross hack. And, it is the intention of the Mercurial project to undo this hack and perform a proper port once Python 3 support in Mercurial is more mature. But, I want to lay out my defense on why I did this and why the Mercurial project is tolerant of this ugly hack.
Individuals within the Mercurial project have wanted to port to Python
3 for years. Until recently, it hasn't been a project priority
because a port was too much work for too little end-user gain. And, on
the technical front, a port was just not practical until Python 3.5.
(Two main blockers were no u'' literals - restored in Python 3.3 -
and no % formatting for b'' literals - restored in 3.5. And as I
understand it, senior members of the Mercurial project had to lobby
Python maintainers pretty hard to get features like % formatting of
b'' literals restored to Python 3.)
Anyway, after a number of failed attempts to initiate the Python 3 port over the years, the Mercurial project started making some positive steps towards Python 3 compatibility, such as switching to absolute imports and addressing syntax issues that allowed modules to be parsed into an AST and even compiled and loadable. These may seem like small steps, but for a larger project, it was a lot of work.
The porting effort hit a large wall when it came time to actually make the AST-valid Python code run on Python 3. Specifically, we had a strings problem.
When you write software that exchanges data between machines - sometimes machines running different operating systems or having different encodings - and there is an expectation that things work the same and data roundtrips accordingly, trying to force text encodings is essentially impossible and inevitably breaks something or someone. It is much easier for Mercurial to operate bytes first and only take text encoding into consideration when absolutely necessary (such as when emitting bytes to the terminal in the wanted encoding or when emitting JSON). That's not to say Mercurial ignores the existence of encodings. Far from it: Mercurial does attempt to normalize some data to Unicode. But it often does so with a special Python type that internally stores the raw byte sequence of the source so that a consumer can choose to operate at the bytes or Unicode level.
Anyway, this means that practically every string variable in Mercurial
is a bytes type (or something that acts like a bytes type). And
since string literals in Python 3 are the str type (which represents
Unicode), that would mean having to prefix almost every '' string
literal in Mercurial with b'' in order to placate Python 3. Having
to update every occurrence of simple primitives that could be statically
transformed automatically felt like busy work. We wanted to spend time
on the meaningful parts of the Python 3 port so we could find
interesting problems and challenges, not toil with mechanical
conversions that add little to no short-term value while simultaneously
increasing cognitive dissonance and quite possibly increasing the odds
of introducing a bug in Python 2. In other words, why should humans
do the work that machines can do for us? Thus, the source-transforming
module importer was born.
While I concede what Mercurial did is a giant hack, I maintain it was the correct thing to do. It has allowed the Python 3 port to move forward without being blocked on the more tedious and invasive transformations that could introduce subtle bugs (including performance regressions) in Python 2. Perfect is the enemy of good. People time is valuable. The source-transforming module importer allowed us to unblock an important project without sinking a lot of people time into it. I'd make that trade-off again.
While I won't encourage others to take this approach to porting to Python 3, if you want to, Mercurial's source is available under a GPL license and the custom module importer could be adapted to any project with minimal modifications. If someone does extract it as reusable code, please leave a comment and I'll update the post to link to it.
« Previous Page -- Next Page »