Why hg.mozilla.org is Slow
December 19, 2014 at 02:40 PM | categories: Mercurial, MozillaAt Mozilla, I often hear statements like Mercurial is slow. That's a very general statement. Depending on the context, it can mean one or more of several things:
- My Mercurial workflow is not very efficient
- hg commands I execute are slow to run
- hg commands I execute appear to stall
- The Mercurial server I'm interfacing with is slow
I want to spend time talking about a specific problem: why hg.mozilla.org (the server) is slow.
What Isn't Slow
If you are talking to hg.mozilla.org over HTTP or HTTPS (https://hg.mozilla.org/), there should not currently be any server performance issues. Our Mercurial HTTP servers are pretty beefy and are able to absorb a lot of load.
If https://hg.mozilla.org/ is slow, chances are:
- You are doing something like cloning a 1+ GB repository.
- You are asking the server to do something really expensive (like generate JSON for 100,000 changesets via the pushlog query interface).
- You don't have a high bandwidth connection to the server.
- There is a network event.
Previous Network Events
There have historically been network capacity issues in the datacenter where hg.mozilla.org is hosted (SCL3).
During Mozlandia, excessive traffic to ftp.mozilla.org essentially saturated the SCL3 network. During this time, requests to hg.mozilla.org were timing out: Mercurial traffic just couldn't traverse the network. Fortunately, events like this are quite rare.
Up until recently, Firefox release automation was effectively overwhelming the network by doing some clownshoesy things.
For example, gaia-central was being cloned all the time We had a ~1.6 GB repository being cloned over a thousand times per day. We were transferring close to 2 TB of gaia-central data out of Mercurial servers per day
We also found issues with pushlogs sending 100+ MB responses.
And the build/tools repo was getting cloned for every job. Ditto for mozharness.
In all, we identified a few terabytes of excessive Mercurial traffic that didn't need to exist. This excessive traffic was saturating the SCL3 network and slowing down not only Mercurial traffic, but other traffic in SCL3 as well.
Fortunately, people from Release Engineering were quick to respond to and fix the problems once they were identified. The problem is now firmly in control. Although, given the scale of Firefox's release automation, any new system that comes online that talks to version control is susceptible to causing server outages. I've already raised this concern when reviewing some TaskCluster code. The thundering herd of automation will be an ongoing concern. But I have plans to further mitigate risk in 2015. Stay tuned.
Looking back at our historical data, it appears that we hit these network saturation limits a few times before we reached a tipping point in early November 2014. Unfortunately, we didn't realize this because up until recently, we didn't have a good source of data coming from the servers. We lacked the tooling to analyze what we had. We lacked the experience to know what to look for. Outages are effective flashlights. We learned a lot and know what we need to do with the data moving forward.
Available Network Bandwidth
One person pinged me on IRC with the comment Git is cloning much faster than Mercurial. I asked for timings and the Mercurial clone wall time for Firefox was much higher than I expected.
The reason was network bandwidth. This person was performing a Git clone between 2 hosts in EC2 but was performing the Mercurial clone between hg.mozilla.org and a host in EC2. In other words, they were partially comparing the performance of a 1 Gbps network against a link over the public internet! When they did a fair comparison by removing the network connection as a variable, the clone times rebounded to what I expected.
The single-homed nature of hg.mozilla.org in a single datacenter in northern California is not only bad for disaster recovery reasons, it also means that machines far away from SCL3 or connecting to SCL3 over a slow network aren't getting optimal performance.
In 2015, expect us to build out a geo-distributed hg.mozilla.org so that connections are hitting a server that is closer and thus faster. This will probably be targeted at Firefox release automation in AWS first. We want those machines to have a fast connection to the server and we want their traffic isolated from the servers developers use so that hiccups in automation don't impact the ability for humans to access and interface with source code.
NFS on SSH Master Server
If you connect to http://hg.mozilla.org/ or https://hg.mozilla.org/, you are hitting a pool of servers behind a load balancer. These servers have repository data stored on local disk, where I/O is fast. In reality, most I/O is serviced by the page cache, so local disks don't come into play.
If you connect to ssh://hg.mozilla.org/, you are hitting a single, master server. Its repository data is hosted on an NFS mount. I/O on the NFS mount is horribly slow. Any I/O intensive operation performed on the master is much, much slower than it should be. Such is the nature of NFS.
We'll be exploring ways to mitigate this performance issue in 2015. But it isn't the biggest source of performance pain, so don't expect anything immediately.
Synchronous Replication During Pushes
When you hg push to hg.mozilla.org, the changes are first made on the SSH/NFS master server. They are subsequently mirrored out to the HTTP read-only slaves.
As is currently implemented, the mirroring process is performed synchronously during the push operation. The server waits for the mirrors to complete (to a reasonable state) before it tells the client the push has completed.
Depending on the repository, the size of the push, and server and network load, mirroring commonly adds 1 to 7 seconds to push times. This is time when a developer is sitting at a terminal, waiting for hg push to complete. The time for Try pushes can be larger: 10 to 20 seconds is not uncommon (but fortunately not the norm).
The current mirroring mechanism is overly simple and prone to many failures and sub-optimal behavior. I plan to work on fixing mirroring in 2015. When I'm done, there should be no user-visible mirroring delay.
Pushlog Replication Inefficiency
Up until yesterday (when we deployed a rewritten pushlog extension, the replication of pushlog data from master to server was very inefficient. Instead of tranferring a delta of pushes since last pull, we were literally copying the underlying SQLite file across the network!
Try's pushlog is ~30 MB. mozilla-central and mozilla-inbound are in the same ballpark. 30 MB x 10 slaves is a lot of data to transfer. These operations were capable of periodically saturating the network, slowing everyone down.
The rewritten pushlog extension performs a delta transfer automatically as part of hg pull. Pushlog synchronization now completes in milliseconds while commonly only consuming a few kilobytes of network traffic.
Early indications reveal that deploying this change yesterday decreased the push times to repositories with long push history by 1-3s.
Try
Pretty much any interaction with the Try repository is guaranteed to have poor performance. The Try repository is doing things that distributed versions control systems weren't designed to do. This includes Git.
If you are using Try, all bets are off. Performance will be problematic until we roll out the headless try repository.
That being said, we've made changes recently to make Try perform better. The median time for pushing to Try has decreased significantly in the past few weeks. The first dip in mid-November was due to upgrading the server from Mercurial 2.5 to Mercurial 3.1 and from converting Try to use generaldelta encoding. The dip this week has been from merging all heads and from deploying the aforementioned pushlog changes. Pushing to Try is now significantly faster than 3 months ago.
Conclusion
Many of the reasons for hg.mozilla.org slowness are known. More often than not, they are due to clownshoes or inefficiencies on Mozilla's part rather than fundamental issues with Mercurial.
We have made significant progress at making hg.mozilla.org faster. But we are not done. We are continuing to invest in fixing the sub-optimal parts and making hg.mozilla.org faster yet. I'm confident that within a few months, nobody will be able to say that the servers are a source of pain like they have been for years.
Furthermore, Mercurial is investing in features to make the wire protocol faster, more efficient, and more powerful. When deployed, these should make pushes faster on any server. They will also enable workflow enhancements, such as Facebook's experimental extension to perform rebases as part of push (eliminating push races and having to manually rebase when you lose the push race).
mach sub-commands
December 18, 2014 at 09:45 AM | categories: Mozillamach - the generic command line dispatching tool that powers the mach command to aid Firefox development - now has support for sub-commands.
You can now create simple and intuitive user interfaces involving sub-actions. e.g.
mach device sync
mach device run
mach device delete
Before, to do something like this would require a universal argument parser or separate mach commands. Both constitute a poor user experience (confusing array of available arguments or proliferation of top-level commands). Both result in mach help being difficult to comprehend. And that's not good for usability and approachability.
Nothing in Firefox currently uses this feature. Although there is an in-progress patch in bug 1108293 for providing a mach command to analyze C/C++ build dependencies. It is my hope that others write useful commands and functionality on top of this feature.
The documentation for mach has also been rewritten. It is now exposed as part of the in-tree Sphinx documentation.
Everyone should thank Andrew Halberstadt for promptly reviewing the changes!
A Crazy Day
December 04, 2014 at 11:34 PM | categories: MozillaToday was one crazy day.
The build peers all sat down with Release Engineering and Axel Hecht to talk l10n packaging. Mike Hommey has a Q1 goal to fix l10n packaging. There is buy-in from Release Engineering on enabling him in his quest to slay dragons. This will make builds faster and will pay off a massive mountain of technical debt that plagues multiple groups at Mozilla.
The Firefox build system contributors sat down with a bunch of Rust people and we talked about what it would take to integrate Rust into the Firefox build system and the path towards shipping a Rust component in Firefox. It sounds like that is going to happen in 2015 (although we're not yet sure what component will be written in Rust). I consider it an achievement that the gathering of both groups didn't result in infinite rabbit holing about system architectures, toolchains, and the build people telling horror stories to wide-eyed Rust people about the crazy things we have to do to build and ship Firefox. Believe me, the temptation was there.
People interested in the build system all sat down and reflected on the state of the build system and where we want to go. We agreed to create a build mode optimized for non-Gecko developers that downloads pre-built binaries - avoiding ~10 minutes of C/C++ compile time for builds. Mark my words, this will be one of those changes that once deployed will cause people to say "I can't believe we went so long without this."
I joined Mark Côté and others to talk about priorities for MozReview. We'll be making major improvements to the UX and integrating static analysis into reviews. Push a patch for review and have machines do some of the work that humans are currently doing! We're tentatively planning a get-together in Toronto in January to sprint towards awesomeness.
I ended the day by giving a long and rambling presentation about version control, with emphasis on Mercurial. I can't help but feel that I talked way too much. There's just so much knowledge to cover. A few people told me afterwards they learned a lot. I'd appreciate feedback if you attended. Anyway, I got a few nods from people as I was saying some somewhat contentious things. It's always good to have validation that I'm not on an island when I say crazy things.
I hope to spend Friday chasing down loose ends from the week. This includes talking to some security gurus about another crazy idea of mine to integrate PGP into the code review and code landing workflow for Firefox. I'll share more details once I get a professional opinion on the security front.
The Mozlandia Tree Outage and Code Review
December 04, 2014 at 08:40 AM | categories: MozReview, Mozilla, code reviewYou may have noticed the Firefox trees were closed for the better part of yesterday.
Long story short, a file containing URLs for Firefox installers was updated to reference https://ftp.mozilla.org/ from http://download-installer.cdn.mozilla.net/. The original, latter host is a CDN. The former is not. When thousands of clients started hitting ftp.mozilla.org, it overwhelmed the servers and network, causing timeouts and other badness.
The change in question was accidental. It went through code review. From a code change standpoint, procedures were followed.
It is tempting to point fingers at the people involved. However, I want us to consider placing blame elsewhere: on the code review tool.
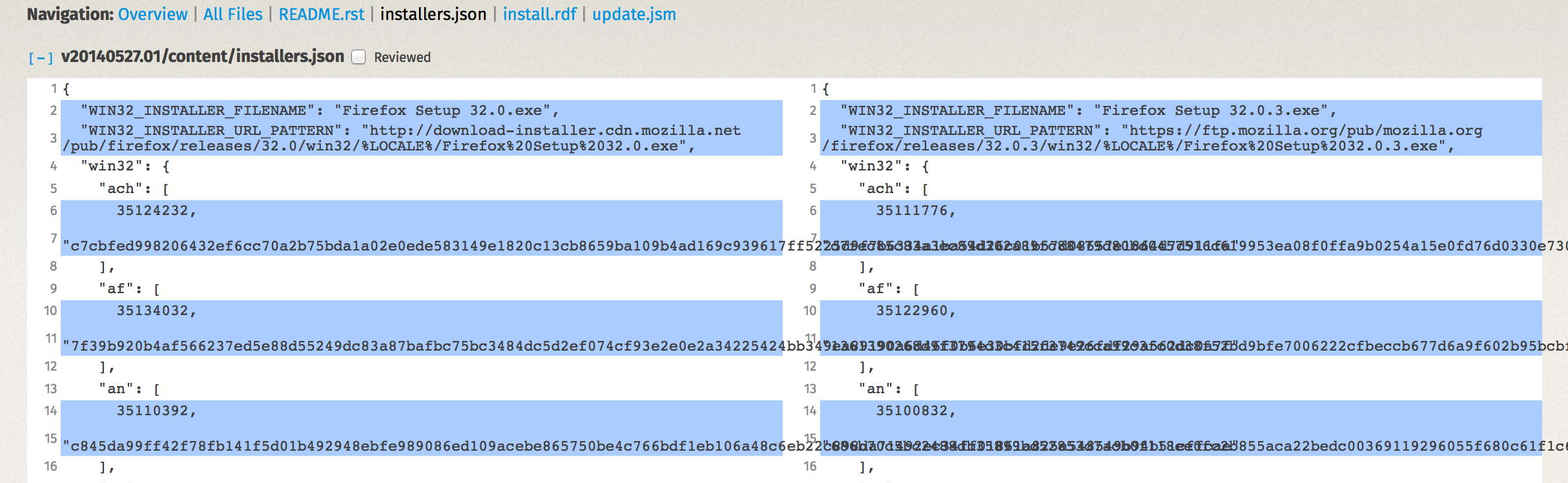
The diff being reviewed was to change the Firefox version number from 32.0 to 32.0.3. If you were asked to review this patch, I'm guessing your eyes would have glanced over everything in the URL except the version number part. I'm pretty sure mine would have.
Let's take a look at what the reviewer saw in Bugzilla/Splinter (click to see full size):
And here is what the reviewer would have seen had the review been conducted in MozReview:
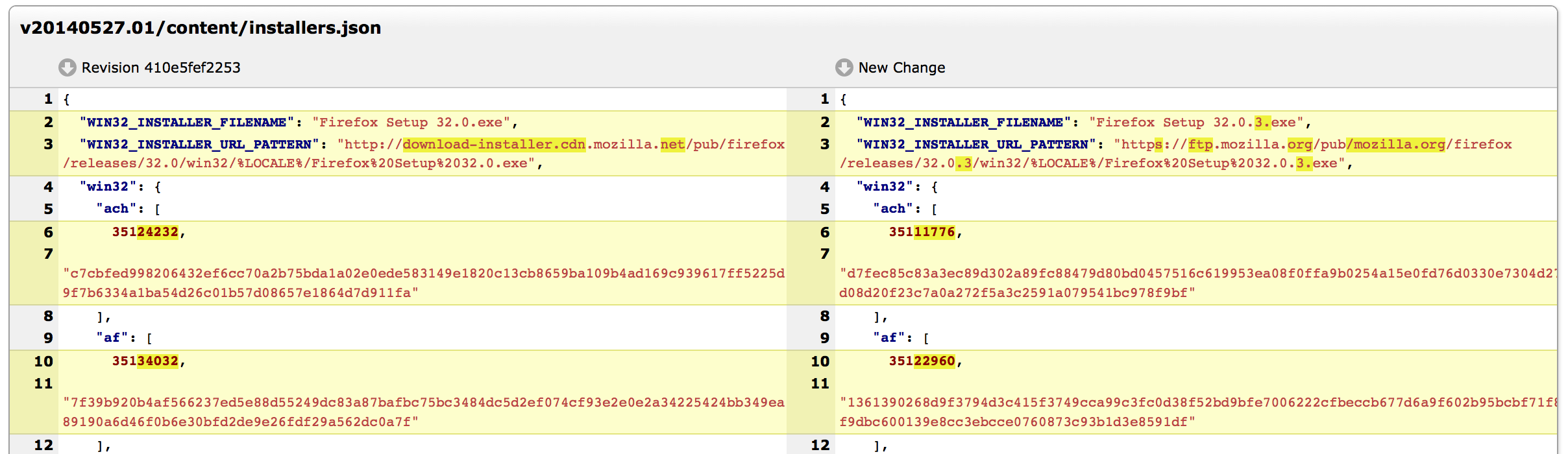
Which tool makes the change of hostname more obvious? Bugzilla/Splinter or MozReview?
MozReview's support for intraline diffs more clearly draws attention to the hostname change. I posit that had this patch been reviewed with MozReview, the chances are greater we wouldn't have had a network outage yesterday.
And it isn't just intraline diffs that make Splinter/Bugzilla a sub-optimal code review tool. I recently blogged about the numerous ways that using Bugzilla for code revie results in harder reviews and buggier code. Every day we continue using Bugzilla/Splinter instead of investing in better code review tools is a day severe bugs like this can and will slip through the cracks.
If there is any silver lining to this outage, I hope it is that we need to double down on our investment in developer tools, particularly code review.
Test Drive the New Headless Try Repository
November 20, 2014 at 02:45 PM | categories: Mercurial, MozillaMercurial and Git both experience scaling pains as the number of heads in a repository approaches infinity. Operations like push and pull slow to a crawl and everyone gets frustrated.
This is the problem Mozilla's Try repository has been dealing with for years. We know the solution doesn't scale. But we've been content kicking the can by resetting the repository (blowing away data) to make the symptoms temporarily go away.
One of my official goals is to ship a scalable Try solution by the end of 2014.
Today, I believe I finally have enough code cobbled together to produce a working concept. And I could use your help testing it.
I would like people to push their Try, code review, and other miscellaneous heads to a special repository. To do this:
$ hg push -r . -f ssh://hg@hg.gregoryszorc.com/gecko-headless
That is:
- Consider the changeset belonging to the working copy
- Allow the creation of new heads
- Send it to the gecko-headless repo on hg.gregoryszorc.com using SSH
Here's what happening.
I have deployed a special repository to my personal server that I believe will behave very similarly to the final solution.
When you push to this repository, instead of your changesets being applied directly to the repository, it siphons them off to a Mercurial bundle. It then saves this bundle somewhere along with some metadata describing what is inside.
When you run hg pull -r
Things this repository doesn't do:
- This repository will not actually send changesets to Try for you.
- You cannot
hg pullorhg clonethe repository and get all of the commits from bundles. This isn't a goal. It will likely never be supported. - We do not yet record a pushlog entry for pushes to the repository.
- The hgweb HTML interface does not yet handle commits that only exist in bundles. People want this to work. It will eventually work.
- Pulling from the repository over HTTP with a vanilla Mercurial install may not preserve phase data.
The purpose of this experiment is to expose the repository to some actual traffic patterns so I can see what's going on and get a feel for real-world performance, variability, bugs, etc. I plan to do all of this in the testing environment. But I'd like some real-world use on the actual Firefox repository to give me peace of mind.
Please report any issues directly to me. Leave a comment here. Ping me on IRC. Send me an email. etc.
Update 2014-11-21: People discovered a bug with pushed changesets accidentally being advanced to the public phase, despite the repository being non-publishing. I have fixed the issue. But you must now push to the repository over SSH, not HTTP.
« Previous Page -- Next Page »