Expanding Apple Ecosystem Access with Open Source, Multi Platform Code Signing
April 25, 2022 at 08:00 AM | categories: Apple, RustA little over one year ago, I announced a project to implement Apple code signing in pure Rust. There have been quite a number of developments since that post and I thought a blog post was in order. So here we are!
But first, some background on why we're here.
Background
(Skip this section if you just want to get to the technical bits.)
Apple runs some of the largest and most profitable software application ecosystems in existence. Gaining access to these ecosystems has traditionally required the use of macOS and membership in the Apple Developer Program.
For the most part this makes sense: if you want to develop applications for Apple operating systems you will likely utilize Apple's operating systems and Apple's official tooling for development and distribution. Sticking to the paved road is a good default!
But many people want more... flexibility. Open source developers, for example, often want to distribute cross-platform applications with minimal effort. There are entire programming language ecosystems where the operating system you are running on is abstracted away as an implementation detail for many applications. By creating a de facto requirement that macOS, iOS, etc development require the direct access to macOS and (often above market priced) Apple hardware, the distribution requirements imposed by Apple's software ecosystems are effectively exclusionary and prevent interested parties from contributing to the ecosystem.
One of the aspects of software distribution on Apple platforms that trips a lot of people up is code signing and notarization. Essentially, you need to:
- Embed a cryptographic signature in applications that effectively attests to its authenticity from an Apple Developer Program associated account. (This is signing.)
- Upload your application to Apple so they can inspect it, verify it meets requirements, likely store a copy of it. Apple then issues their own cryptographic signature called a notarization ticket which then needs to be stapled/attached to the application being distributed so Apple operating systems can trust it. (This is notarization.)
Historically, these steps required Apple proprietary software run exclusively from macOS. This means that even if you are in a software ecosystem like Rust, Go, or the web platform where you can cross-compile apps without direct access to macOS (testing is obviously a different story), you would still need macOS somewhere if you wanted to sign and notarize your application. And signing and notarization is effectively required on macOS due to default security settings. On mobile platforms like iOS, it is impossible to distribute applications that aren't signed and notarized unless you are running a jailbreaked device.
A lot of people (myself included) have grumbled at these requirements. Why should I be forced to involve an Apple machine as part of my software release process if I don't need macOS to build my application? Why do I have to go through a convoluted dance to sign and notarize my application at release time - can't it be more streamlined?
When I looked at this space last year, I saw some obvious inefficiencies and room to improve. So as I said then, I foolishly set out to reimplement Apple code signing so developers would have more flexibility and opportunity for distributing applications to Apple's ecosystems.
The ultimate goal of this work is to expand Apple ecosystem access to more developers. A year later, I believe I'm delivering a product capable of doing this.
One Year Later
Foremost, I'm excited to announce release of
rcodesign 0.14.0.
This is the first time I'm publishing pre-built binaries (Linux, Windows, and macOS)
of rcodesign. This reflects my confidence in the relative maturity of the
software.
In case you are wondering, yes, the macOS rcodesign executable is self-signed:
it was signed by a GitHub Actions Linux runner using a code signing certificate
exclusive to a YubiKey. That YubiKey was plugged into a Windows 11 desktop next to
my desk. The rcodesign executable was not copied between machines as part of the
signing operation. Read on to learn about the sorcery that made this possible.
A lot has changed in the apple-codesign project / Rust crate in the last year! Just look at the changelog!
The project was renamed from tugger-apple-codesign.
(If you installed via cargo install, you'll need to
cargo install --force apple-codesign to force Cargo to overwrite the rcodesign
executable with one from a different crate.)
The rcodesign CLI executable is still there and more powerful than ever.
You can still sign Apple applications from Linux, Windows, macOS, and any other
platform you can get the Rust program to compile on.
There is now Sphinx documentation for the project. This is published on readthedocs.io alongside PyOxidizer's documentation (because I'm using a monorepo). There's some general documentation in there, such as a guide on how to selectively bypass Gatekeeper by deploying your own alternative code signing PKI to parallel Apple's. (This seems like something many companies would want but for whatever reason I'm not aware of anyone doing this - possibly because very few people understand how these systems work.)
There are bug fixes galore. When I look back at the state of rcodesign
when I first blogged about it, I think of how naive I was. There were a myriad
of applications that wouldn't pass notarization because of a long tail of bugs.
There are still known issues. But I believe many applications will
successfully sign and notarize now. I consider failures novel and worthy of
bug reports - so please report them!
Read on to learn about some of the notable improvements in the past year (many of them occurring in the last two months).
Support for Signing Bundles, DMGs, and .pkg Installers
When I announced this project last year, only Mach-O binaries and trivially
simple .app bundles were signable. And even then there were a ton of subtle
issues.
rcodesign sign can now sign more complex bundles, including many nested
bundles. There are reports of iOS app bundles signing correctly! (However, we
don't yet have good end-user documentation for signing iOS apps. I will gladly
accept PRs to improve the documentation!)
The tool also gained support for signing .dmg disk image files and .pkg
flat package installers.
Known limitations with signing are now documented in the Sphinx docs.
I believe rcodesign now supports signing all the major file formats used
for Apple software distribution. If you find something that doesn't sign
and it isn't documented as a known issue with an existing GitHub issue tracking
it, please report it!
Support for Notarization on Linux, Windows, and macOS
Apple publishes a Java tool named Transporter that enables you to upload artifacts to Apple for notarization. They make this tool available for Linux, Windows, and of course macOS.
While this tool isn't open source (as far as I know), usage of this tool enables you to notarize from Linux and Windows while still using Apple's official tooling for communicating with their servers.
rcodesign now has support for invoking Transporter and uploading artifacts
to Apple for notarization. We now support notarizing bundles, .dmg disk
images, and .pkg flat installer packages. I've successfully notarized all
of these application types from Linux.
(I'm capable of implementing
an alternative uploader in pure Rust but without assurances that Apple won't
bring down the ban hammer for violating terms of use, this is a bridge I'm
not yet willing to cross. The requirement to use Transporter is literally the
only thing standing in the way of making rcodesign an all-in-one single
file executable tool for signing and notarizing Apple software and I really
wish I could deliver this user experience win without reprisal.)
With support for both signing and notarizing all application types, it is now possible to release Apple software without macOS involved in your release process.
YubiKey Integration
I try to use my YubiKeys as much as possible because a secret or private key stored on a YubiKey is likely more secure than a secret or private key sitting around on a filesystem somewhere. If you hack my machine, you can likely gain access to my private keys. But you will need physical access to my YubiKey and to compel or coerce me into unlocking it in order to gain access to its private keys.
rcodesign now has support for using YubiKeys for signing operations.
This does require an off-by-default smartcard Cargo feature. So if
building manually you'll need to e.g.
cargo install --features smartcard apple-codesign.
The YubiKey integration comes courtesy of the amazing
yubikey Rust crate. This crate will speak
directly to the smartcard APIs built into macOS and Windows. So if you have an
rcodesign build with YubiKey support enabled, YubiKeys should
just work. Try it by plugging in your YubiKey and running
rcodesign smartcard-scan.
YubiKey integration has its own documentation.
I even implemented some commands to make it easy to manage the code signing
certificates on your YubiKey. For example, you can run
rcodesign smartcard-generate-key --smartcard-slot 9c to generate a new private
key directly on the device and then
rcodesign generate-certificate-signing-request --smartcard-slot 9c --csr-pem-path csr.pem
to export that certificate to a Certificate Signing Request (CSR), which you can
exchange for an Applie-issued signing certificate at developer.apple.com. This
means you can easily create code signing certificates whose private key was
generated directly on the hardware device and can never be exported.
Generating keys this way is widely considered to be more secure than storing
keys in software vaults, like Apple's Keychains.
Remote Code Signing
The feature I'm most excited about is what I'm calling remote code signing.
Remote code signing allows you to delegate the low-level cryptographic signature operations in code signing to a separate machine.
It's probably easiest to just demonstrate what it can do.
Earlier today I signed a macOS universal Mach-O executable from a GitHub-hosted Linux GitHub Actions runner using a YubiKey physically attached to the Windows 11 machine next to my desk at home. The signed application was not copied between machines.
Here's how I did it.
I have a GitHub Actions workflow that calls rcodesign sign --remote-signer.
I manually triggered that workflow and started watching the near real time
job output with my browser. Here's a screenshot of the job logs:
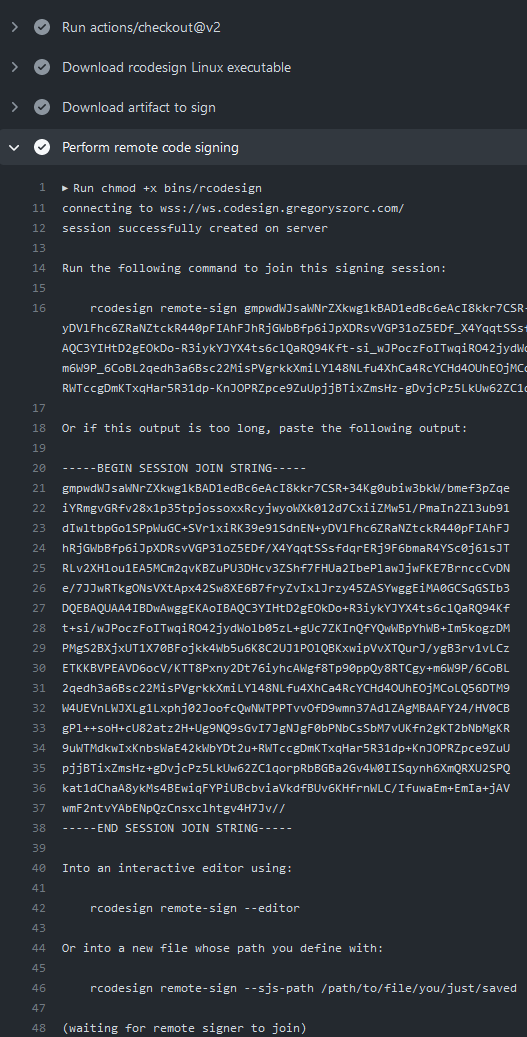
rcodesign sign --remote-signer prints out some instructions (including a
wall of base64 encoded data) for what to do next. Importantly, it requests that
someone else run rcodesign remote-sign to continue the signing process.
And here's a screenshot of me doing that from the Windows terminal:
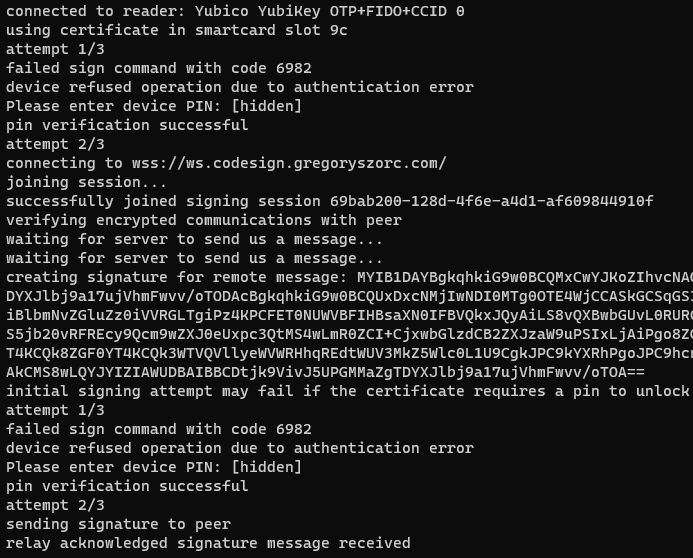
This log shows us connecting and authenticating with the YubiKey along with some status updates regarding speaking to a remote server.
Finally, here's a screenshot of the GitHub Actions job output after I ran that command on my Windows machine:
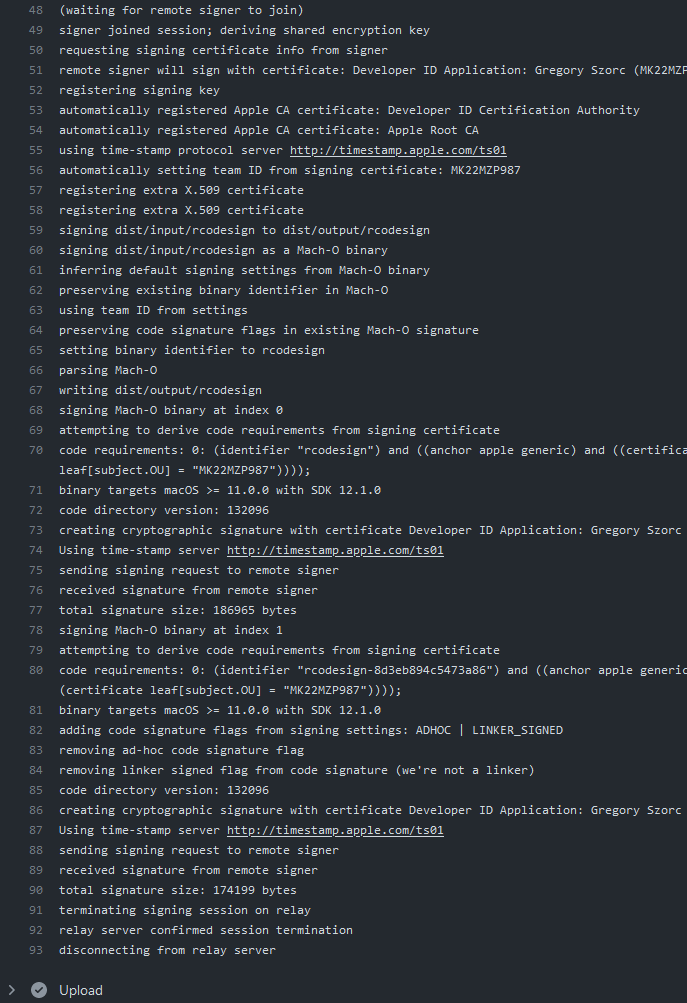
Remote signing enabled me to sign a macOS application from a GitHub Actions runner operated by GitHub while using a code signing certificate securely stored on my YubiKey plugged into a Windows machine hundreds of kilometers away from the GitHub Actions runner. Magic, right?
What's happening here is the 2 rcodesign processes are communicating
with each other via websockets bridged by a central relay server.
(I operate a
default server free of charge.
The server is open source and a Terraform module is available if you want
to run your own server with hopefully just a few minutes of effort.)
When the initiating machine wants to create a signature, it sends a
message back to the signer requesting a cryptographic signature. The
signature is then sent back to the initiator, who incorporates it.
I designed this feature with automated releases from CI systems (like GitHub Actions) in mind. I wanted a way where I could streamline the code signing and release process of applications without having to give a low trust machine in CI ~unlimited access to my private signing key. But the more I thought about it the more I realized there are likely many other scenarios where this could be useful. Have you ever emailed or Dropboxed an application for someone else to sign because you don't have an Apple issued code signing certificate? Now you have an alternative solution that doesn't require copying files around! As long as you can see the log output from the initiating machine or have that output communicated to you (say over a chat application or email), you can remotely sign files on another machine!
An Aside on the Security of Remote Signing
At this point, I'm confident the more security conscious among you have been grimacing for a few paragraphs now. Websockets through a central server operated by a 3rd party?! Giving remote machines access to perform code signing against arbitrary content?! Your fears and skepticism are 100% justified: I'd be thinking the same thing!
I fully recognize that a service that facilitates remote code signing makes for a very lucrative attack target! If abused, it could be used to coerce parties with valid code signing certificates to sign unwanted code, like malware. There are many, many, many wrong ways to implement such a feature. I pondered for hours about the threat modeling and how to make this feature as secure as possible.
Remote Code Signing Design and Security Considerations captures some of my high level design goals and security assessments. And Remote Code Signing Protocol goes into detail about the communications protocol, including the crypto (actual cryptography, not the fad) involved. The key takeaways are the protocol and server are designed such that a malicious server or man-in-the-middle can not forge signature requests. Signing sessions expire after a few minutes and 3rd parties (or the server) can't inject malicious messages that would result in unwanted signatures. There is an initial handshake to derive a session ephemeral shared encryption key and from there symmetric encryption keys are used so all meaningful messages between peers are end-to-end encrypted. About the worst a malicious server could do is conduct a denial of service. This is by design.
As I argue in Security Analysis in the Bigger Picture, I believe that my implementation of remote signing is more secure than many common practices because common practices today entail making copies of private keys and giving low trust machines (like CI workers) access to private keys. Or files are copied around without cryptographic chain-of-custody to prove against tampering. Yes, remote signing introduces a vector for remote access to use signing keys. But practiced as I intended, remote signing can eliminate the need to copy private keys or grant ~unlimited access to them. From a threat modeling perspective, I think the net restriction in key access makes remote signing more secure than the private key management practices by many today.
All that being said, the giant asterisk here is I implemented my own cryptosystem to achieve end-to-end message security. If there are bugs in the design or implementation, that cryptosystem could come crashing down, bringing defenses against message forgery with it. At that point, a malicious server or privileged network actor could potentially coerce someone into signing unwanted software. But this is likely the extent of the damage: an offline attack against the signing key should not be possible since signing requires presence and since the private key is never transmitted over the wire. Even without the end-to-end encryption, the system is arguably more secure than leaving your private key lingering around as an easily exfiltrated CI secret (or similar).
(I apologize to every cryptographer I worked with at Mozilla who beat into me the commandment that thou shall not roll their own crypto: I have sinned and I feel remorseful.)
Cryptography is hard. And I'm sure I made plenty of subtle mistakes. Issue #552 tracks getting an audit of this protocol and code performed. And the aforementioned protocol design docs call out some of the places where I question decisions I've made.
If you would be interested in doing a security review on this feature, please get in touch on issue #552 or send me an email. If there's one immediate outcome I'd like from this blog post it would be for some white hat^Hknight to show up and give me peace of mind about the cryptosystem implementation.
Until then, please assume the end-to-end encryption is completely flawed. Consider asking someone with security or cryptographer in their job title for their opinion on whether this feature is safe for you to use. Hopefully we'll get a security review done soon and this caveat can go away!
If you do want to use this feature, Remote Code Signing contains some usage documentation, including how to use it with GitHub Actions. (I could also use some help productionizing a reusable GitHub Action to make this more turnkey! Although I'm hesitant to do it before I know the cryptosystem is sound.)
That was a long introduction to remote code signing. But I couldn't in good faith present the feature without addressing the security aspect. Hopefully I didn't scare you away! Traditional / local signing should have no security concerns (beyond the willingness to run software written by somebody you probably don't know, of course).
Apple Keychain Support
As of today's 0.14 release we now have early support for signing with code signing certificates stored in Apple Keychains! If you created your Apple code signing certificates in Keychain Access or Xcode, this is probably where you code signing certificates live.
I held off implementing this for the longest time because I didn't perceive
there to be a benefit: if you are on macOS, just use Apple's official tooling.
But with rcodesign gaining support for remote code signing and some other
features that could make it a compelling replacement for Apple tooling on
all platforms, I figured we should provide the feature so we stop discouraging
people to export private keys from Keychains.
This integration is very young and there's still a lot that can be done, such as automatically using an appropriate signing certificate based on what you are signing. Please file feature request issues if there's a must-have feature you are missing!
Better Debugging of Failures
Apple's code signing is complex. It is easy for there to be subtle differences
between Apple's tooling and rcodesign.
rcodesign now has print-signature-info and diff-signatures commands to
dump and compare YAML metadata pertinent to code signing to make it easier to
compare behavior between code signing implementations and even multiple
signing operations.
The documentation around debugging and reporting bugs now emphasizes using these tools to help identify bugs.
A Request For Users and Feedback
I now believe rcodesign to be generally usable. I've thrown a lot of
random software at it and I feel like most of the big bugs and major missing
features are behind us.
But I also feel it hasn't yet received wide enough attention to have confidence in that assessment.
If you want to help the development of this tool, the most important actions you can take are to attempt signing / notarization operations with it and report your results.
Does rcodesign spark joy? Please leave a comment in the
GitHub discussion for the latest release!
Does rcodesign not work? I would very much appreciate a bug report!
Details on how to file good bugs are
in the docs.
Have general feedback? UI is confusing? Documentation is insufficient? Leave a comment in the aforementioned discussion. Or create a GitHub issue if you think it is actionable. I can't fix what I don't know about!
Have private feedback? Send me an email.
Conclusion
I could write thousands of words about all I learned from hacking on this project.
I've learned way too much about too many standards and specifications in the
crypto space. RFCs 2986, 3161, 3280, 3281, 3447, 4210, 4519, 5280, 5480,
5652, 5869, 5915, 5958, and 8017 plus probably a few more. How cryptographic
primitives are stored and expressed: ASN.1, OIDs, BER, DER, PEM, SPKI,
PKCS#1, PKCS#8. You can show me the raw parse tree for an ASN.1 data structure
and I can probably tell you what RFC defines it. I'm not proud of this. But
I will say actually knowing what every field in an X.509 certificate does
or the many formats that cryptographic keys are expressed in seems empowering.
Before, I would just search for the openssl incantation to do something.
Now, I know which ASN.1 data structures are involved and how to manipulate
the fields within.
I've learned way too much around minutia around how Apple code signing actually works. The mechanism is way too complex for something in the security space. There was at least one high profile Gatekeeper bug in the past year allowing improperly signed code to run. I suspect there will be more: the surface area to exploit is just too large.
I think I'm proud of building an open source implementation of Apple's code signing. To my knowledge nobody else has done this outside of Apple. At least not to the degree I have. Then factor in that I was able to do this without access (or willingness) to look at Apple source code and much of the progress was achieved by diffing and comparing results with Apple's tooling. Hours of staring at diffoscope and comparing binary data structures. Hours of trying to find the magical settings that enabled a SHA-1 or SHA-256 digest to agree. It was tedious work for sure. I'll likely never see a financial return on the time equivalent it took me to develop this software. But, I suppose I can nerd brag that I was able to implement this!
But the real reward for this work will be if it opens up avenues to more (open source) projects distributing to the Apple ecosystems. This has historically been challenging for multiple reasons and many open source projects have avoided official / proper distribution channels to avoid the pain (or in some cases because of philosophical disagreements with the premise of having a walled software garden in the first place). I suspect things will only get worse, as I feel it is inevitable Apple clamps down on signing and notarization requirements on macOS due to the rising costs of malware and ransomware. So having an alternative, open source, and multi-platform implementation of Apple code signing seems like something important that should exist in order to provide opportunities to otherwise excluded developers. I would be humbled if my work empowers others. And this is all the reward I need.
Bulk Analyze Linux Packages with Linux Package Analyzer
January 09, 2022 at 09:10 PM | categories: packaging, RustI've frequently wanted to ask random questions about Linux packages and binaries:
- Which packages provide a file X?
- Which binaries link against a library X?
- Which libraries/packages define/export a symbol X?
- Which binaries reference an undefined symbol X?
- Which features of ELF are in common use?
- Which x86 instructions are in a binary?
- What are the most common ELF section names and their sizes?
- What are the differences between package X in distributions A and B?
- Which ELF binaries have the most relocations?
- And many more.
So, I built Linux Package Analyzer to facilitate answering questions like this.
Linux Package Analyzer is a Rust crate providing the lpa CLI tool. lpa currently
supports importing Debian and RPM package repositories (the most popular Linux
packaging formats) into a local SQLite database so subsequent analysis can be
efficiently performed offline. In essence:
- Run
lpa import-debian-repositoryorlpa import-rpm-repositoryand point the tool at the base URL of a Linux package repository. - Package indices are fetched.
- Discovered
.deband.rpmfiles are downloaded. - Installed files within each package archive are inspected.
- Binary/ELF files have their executable sections disassembled.
- Results are stored in a local SQLite database for subsequent analysis.
The LPA-built database currently stores the following:
- Imported packages (name, version, source URL).
- Installed files within each package (path, size).
- ELF file information (parsed fields from header, number of relocations,
important metadata from the
.dynamicsection, etc). - ELF sections (number, type, flags, address, file offset, etc).
- Dynamic libraries required by ELF files.
- ELF symbols (name, demangled name, type constant, binding, visibility, version string, etc).
- For x86 architectures, counts of unique instructions in each ELF file and counts of instructions referencing specific registers.
Using a command like lpa import-debian-repository --components main,multiverse,restricted,universe
--architectures amd64 http://us.archive.ubuntu.com/ubuntu impish, I can import
the (currently) ~96 GB of package data from 63,720 packages defining Ubuntu 21.10
to a local ~12 GB SQLite database and answer tons of random questions. Interesting
insights yielded so far include:
- The entirety of the package ecosystem for amd64 consists of 63,720 packages providing 6,704,222 files (168,730 of them ELF binaries) comprising 355,700,362,973 bytes in total.
- Within the 168,730 ELF binaries are 5,286,210 total sections having 606,175 distinct names. There are also 116,688,943 symbols in symbol tables (debugging info is not included and local symbols not imported or exported are often not present in symbol tables) across 19,085,540 distinct symbol names. The sum of all the unique symbol names is 1,263,441,355 bytes and 4,574,688,289 bytes if you count occurrences across all symbol tables (this might be an over count due to how ELF string tables work).
- The longest demangled ELF symbol is 271,800 characters and is defined in
the file
usr/lib/x86_64-linux-gnu/libmshr.so.2019.2.0.dev0provided by thelibmshr2019.2package. - The longest non-mangled ELF symbol is 5,321 characters and is defined in multiple files/packages, as it is part of a library provided by GCC.
- Only 145 packages have files with indirect functions (IFUNCs). If you discard duplicates (mainly from GCC and glibc), you are left with ~11 packages. This does not appear to be a popular ELF feature!
- With 54,764 references in symbol tables,
strlenappears to be the most (recognized) widely used libc symbol. It even bestsmemcpy(52,726) andfree(42,603). MOVis the most frequent x86 instruction, followed byCALL. (I could write an entire blog post about observations about x86 instruction use.)
There's a trove of data in the SQLite database and the lpa commands only
expose a fraction of it. I reckon a lot of interesting tweets, blog posts,
research papers, and more could be derived from the data that lpa assembles.
lpa does all of its work in-process using pure Rust. The Debian and RPM
repository interaction is handled via the
debian-packaging and
rpm-repository crates (which I
wrote). ELF file parsing is handled by the (amazing)
object crate. And x86 disassembling via
the iced-x86 crate. Many tools similar
to lpa call out to other processes to interface with .deb/.rpm packages,
parse ELF files, disassemble x86, etc. Doing this in pure Rust makes life so
much simpler as all the functionality is self-contained and I don't have to
worry about run-time dependencies for random tools. This means that lpa
should just work from Windows, macOS, and other non-Linux environments.
Linux Package Analyzer is very much in its infancy. And I don't really have a grand vision for it. (I built it and some of the packaging code it is built on) in support of some even grander projects I have cooking.) Please file bugs, feature requests, and pull requests in GitHub. The project is currently part of the PyOxidizer repo (because I like monorepos). But I may pull it and other os/packaging/toolchain code into a new monorepo since target audiences are different.
I hope others find this tool useful!
Rust Implementation of Debian Packaging Primitives
January 03, 2022 at 04:00 PM | categories: packaging, RustDoes your Linux distribution use tools with apt in their name to manage
system packages? If so, your system packages are using Debian packaging.
Most tools interfacing with Debian packages (.deb files) and repositories
use functionality provided by the apt
repository. This repository provides libraries like libapt as well as
tools like apt-get and apt. Most of the functionality is implemented in
C++.
I wanted to raise awareness that I've begun implementing Debian packaging
primitives in pure Rust. The debian-packaging crate is
published on crates.io. For
now, it is developed inside the
PyOxidizer repository (because I
like monorepos).
So far, a handful of useful functionality is implemented:
- Parsing and serializing control files
- Reading repository indices files and parsing their content.
- Reading HTTP hosted repositories.
- Publishing repositories to the filesystem and S3.
- Writing changelog files.
- Reading and writing
.debfiles. - Copying repositories.
- Creating repositories.
- PGP signing and verification operations.
- Parsing and sorting version strings.
- Dependency syntax parsing.
- Dependency resolution.
Hopefully the documentation contains all you would want to know for how to use the crate.
The crate is designed to be used as a library so any Rust program can (hopefully) easily tap the power of the Debian packaging ecosystem.
As with most software, there are likely several bugs and many features not yet
implemented. But I have bulk downloaded the entirety of some distribution's
repositories without running into obvious parse/reading failures. So I'm
reasonably confident that important parts of the code (like control file parsing,
repository indices file handling, and .deb file reading) work as advertised.
Hopefully someone out there finds this work useful!
Why You Shouldn't Use Git LFS
May 12, 2021 at 10:30 AM | categories: Mercurial, GitI have long held the opinion that you should avoid Git LFS if possible. Since people keeping asking me why, I figured I'd capture my thoughts in a blog post so I have something to refer them to.
Here are my reasons for not using Git LFS.
Git LFS is a Stop Gap Solution
Git LFS was developed outside the official Git project to fulfill a very real market need that Git didn't/doesn't handle large files very well.
I believe it is inevitable that Git will gain better support for handling of large files, as this seems like a critical feature for a popular version control tool.
If you make this long bet, LFS is only an interim solution and its value proposition disappears after Git has better native support for large files.
LFS as a stop gap solution would be tolerable except for the fact that...
Git LFS is a One Way Door
The adoption or removal of Git LFS in a repository is an irreversible decision that requires rewriting history and losing your original commit SHAs.
In some contexts, rewriting history is tolerable. In many others, it is an extremely expensive proposition. My experience maintaining version control in professional contexts aligns with the opinion that rewriting history is expensive and should only be considered a measure of last resort. Maybe if tools made it easier to rewrite history without the negative consequences (e.g. GitHub would redirect references to old SHA1 in URLs and API calls) I would change my opinion here. Until that day, the drawbacks of losing history are just too high to stomach for many.
The reason adoption or removal of LFS is irreversible is due to the way Git LFS works. What LFS does is change the blob content that a Git commit/tree references. Instead of the content itself, it stores a pointer to the content. At checkout and commit time, LFS blobs/records are treated specially via a mechanism in Git that allows content to be rewritten as it moves between Git's core storage and its materialized representation. (The same filtering mechanism is responsible for normalizing line endings in text files. Although that feature is built into the core Git product and doesn't work exactly the same way. But the principles are the same.)
Since the LFS pointer is part of the Merkle tree that a Git commit derives from, you can't add or remove LFS from a repo without rewriting existing Git commit SHAs.
I want to explicitly call out that even if a rewrite is acceptable in the short term, things may change in the future. If you adopt LFS today, you are committing to a) running an LFS server forever b) incurring a history rewrite in the future in order to remove LFS from your repo, or c) ceasing to provide an LFS server and locking out people from using older Git commits. I don't think any of these are great options: I would prefer if there were a way to offboard from LFS in the future with minimal disruption. This is theoretically possible, but it requires the Git core product to recognize LFS blobs/records natively. There's no guarantee this will happen. So adoption of Git LFS is a one way door that can't be easily reversed.
LFS is More Complexity
LFS is more complex for Git end users.
Git users have to install, configure, and sometimes know about the existence of Git LFS. Version control should just work. Large file handling should just work. End-users shouldn't have to care that large files are handled slightly differently from small files.
The usability of Git LFS is generally pretty good. However, there's an upper limit on that usability as long as LFS exists outside the core Git product. And LFS will likely never be integrated into the core Git product because the Git maintainers know that LFS is only a stop gap solution. They would rather solve large files storage correctly than ~forever carry the legacy baggage of having to support LFS in the core product.
LFS is more complexity for Git server operators as well. Instead of a self-contained Git repository and server to support, you now have to support a likely separate HTTP server to facilitate LFS access. This isn't the hardest thing in the world, especially since we're talking about key-value blob storage, which is arguably a solved problem. But it's another piece of infrastructure to support and secure and it increases the surface area of complexity instead of minimizing it. As a server operator, I would much prefer if the large file storage were integrated into the core Git product and I simply needed to provide some settings for it to just work.
Mercurial Does LFS Slightly Better
Since I'm a maintainer of the Mercurial version control tool, I thought I'd throw out how Mercurial handles large file storage better than Git. Mercurial's large file handling isn't great, but I believe it is strictly better with regards to the trade-offs of adopting large file storage.
In Mercurial, use of LFS is a dynamic feature that server/repo operators can choose to enable or disable whenever they want. When the Mercurial server sends file content to a client, presence of external/LFS storage is a flag set on that file revision. Essentially, the flag says the data you are receiving is an LFS record, not the file content itself and the client knows how to resolve that record into content.
Conceptually, this is little different from Git LFS records in terms of content resolution. However, the big difference is this flag is part of the repository interchange data, not the core repository data as it is with Git. Since this flag isn't part of the Merkle tree used to derive the commit SHA, adding, removing, or altering the content of the LFS records doesn't require rewriting commit SHAs. The tracked content SHA - the data now stored in LFS - is still tracked as part of the Merkle tree, so the integrity of the commit / repository can still be verified.
In Mercurial, the choice of whether to use LFS and what to use LFS for is made by the server operator and settings can change over time. For example, you could start with no use of LFS and then one day decide to use LFS for all file revisions larger than 10 MB. Then a year later you lower that to all revisions larger than 1 MB. Then a year after that Mercurial gains better native support for large files and you decide to stop using LFS altogether.
Also in Mercurial, it is possible for clients to push a large file inline as part of the push operation. When the server sees that large file, it can be like this is a large file: I'm going to add it to the blob store and advertise it as LFS. Because the large file record isn't part of the Merkle tree, you can have nice things like this.
I suspect it is only a matter of time before Git's wire protocol learns the ability to dynamically advertise remote servers for content retrieval and this feature will be leveraged for better large file handling. Until that day, I suppose we're stuck with having to rewrite history with LFS and/or funnel large blobs through Git natively, with all the pain that entails.
Conclusion
This post summarized reasons to avoid Git LFS. Are there justifiable scenarios for using LFS? Absolutely! If you insist on using Git and insist on tracking many large files in version control, you should definitely consider LFS. (Although, if you are a heavy user of large files in version control, I would consider Plastic SCM instead, as they seem to have the most mature solution for large files handling.)
The main point of this post is to highlight some drawbacks with using Git LFS because Git LFS is most definitely not a magic bullet. If you can stomach the short and long term effects of Git LFS adoption, by all means, use Git LFS. But please make an informed decision either way.
Pure Rust Implementation of Apple Code Signing
April 14, 2021 at 01:45 PM | categories: PyOxidizer, Apple, RustA few weeks ago I (foolishly?) set out to implement Apple code signing
(what Apple's codesign tool does) in pure Rust.
I wanted to quickly announce on this blog the existence of the project and
the news that as of a few minutes ago, the tugger-apple-codesign crate
implementing the code signing functionality is now
published on crates.io!
So, you can now sign Apple binaries and bundles on non-Apple hardware by doing something like this:
$ cargo install tugger-apple-codesign
$ rcodesign sign /path/to/input /path/to/output
Current features include:
- Robust support for parsing embedded signatures and most related data
structures.
rcodesign extractcan be used to extract various signature data in raw or human readable form. - Parse and verify RFC 5652 Cryptographic Message Syntax (CMS) signature data.
- Sign binaries. If a code signing certificate key pair is provided, a CMS signature will be created. This includes support for Time-Stamp Protocol (TSP) / RFC 3161 tokens. If no key pair is provided, you get an ad-hoc signature.
- Signing bundles. Nested bundles and binaries will automatically be signed.
Non-code resources will be digested and a
CodeResourcesXML file will be produced.
The most notable missing features are:
- No support for obtaining signing keys from keychains. If you want to sign with a cryptographic key pair, you'll need to point the tool at a PEM encoded key pair and CA chain.
- No support for parsing the Code Signing Requirements language. We can parse the
binary encoding produced by
csreq -band convert it back to this DSL. But we don't parse the human friendly language. - No support for notarization.
All of these could likely be implemented. However, I am not actively working on any of these features. If you would like to contribute support, make noise in the GitHub issue tracker.
The Rust API, CLI, and documentation are still a bit rough around the edges. I
haven't performed thorough QA on aspects of the functionality. However, the
tool is able to produce signed binaries that Apple's canonical codesign tool
says are well-formed. So I'm reasonably confident some of the functionality
works as intended. If you find bugs or missing features, please
report them on GitHub. Or even
better: submit pull requests!
As part of this project, I also created and published the cryptographic-message-syntax crate, which is a pure Rust partial implementation of RFC 5652, which defines the cryptographic message signing mechanism. This RFC is a bit dated and seems to have been superseded by RPKI. So you may want to look elsewhere before inventing new signing mechanisms that use this format.
Finally, it appears the Windows code signing mechanism (Authenticode) also uses RFC 5652 (or a variant thereof) for cryptographic signatures. So by implementing Apple code signatures, I believe I've done most of the legwork to implement Windows/PE signing! I'll probably implement Windows signing in a new crate whenever I hook up automatic code signing to PyOxidizer, which was the impetus for this work (I want to make it possible to build distributable Apple programs without Apple hardware, using as many open source Rust components as possible).
« Previous Page -- Next Page »