The State of Mercurial at Mozilla
May 13, 2013 at 01:25 PM | categories: Mercurial, MozillaI have an opinion on the usage of Mercurial at Mozilla: it stinks.
Here's why.
The server is configured poorly
Our Mozilla server, hg.mozilla.org, is currently running Mercurial 2.0.2. In terms of Mercurial features, stability, and performance, we are light years behind.
You know that annoying phases configuration you need to set when pushing to Try? That's because the server isn't new enough to tell the client the same thing the configuration option does. It will be fixed when the server is upgraded to 2.1+.
Furthermore, we are running the server over NFS, which introduces known badness, including slowness.
I believe we blame Mercurial for issues that would go away if we configured the Mercurial server properly.
Fortunately, it appears the upgrade to 2.5 is near and I've heard we're moving from NFS to local disk storage as part of that. This should go a long way to making the server better. The upgrade can't happen soon enough.
User education is poor
I think a lot of people are ignorant on the features and abilities of Mercurial.
I commonly hear people are dissatisfied with the behavior of their Mercurial client. They encounter performance issues, bugs, corruption, etc. Nine times out of ten this is due to running an old Mercurial release. Just last Friday someone on my team asked me about weird behavior involving file case. My first question: what version of Mercurial are you using? He was running 2.0.2. I told him to upgrade to 2.5+. It fixed his problem. If you aren't running Mercurial 2.5 or newer, upgrade immediately.
I've heard people say we should switch to Git because Git has feature X. Most of the time, Mercurial has these features. Unfortunately, people just don't realize it. When I point them at Mercurial's extensions list their eyes light up and they thank me for making their lives easier.
I think a problem is a lot of new Mozilla contributors knew Git before and only pick up the bare essentials of Mercurial that allow them to land patches. They prefer Git because it is familiar and just don't bother to pick up Mercurial. The potential of Mercurial is thus lost on them.
Perhaps we should have a brown bag and/or better documentation on getting the most out of Mercurial?
The branching model is far from ideal
For Gecko/Firefox development, we maintain separate repositories for the trunk and release branches. This introduces all kinds of annoying.
We should not have separate repositories for central, inbound, aurora, beta, release, etc. We should be using some combination of branches and bookmarks and have all the release heads in one repository, just like how the GitHub mirror is configured.
As an experiment, I created a unified Mercurial repository. Each current repository is tracked as a bookmark (there are instructions for reproducing this). Unfortunately, the web interface isn't showing bookmarks (perhaps because the version of Mercurial is too old?), so you'll have to clone the repository to play around. Just run hg bookmarks and e.g. hg up aurora after cloning. Warning: I'm not actively synchronizing this repository, so don't rely on it being up to date.
A Mercurial contributor (who is familiar with Mozilla's development model) suggested we use Mercurial branches for every Gecko release (20, 21, 22, etc). I think this and other uses of branches and bookmarks are ideas worth exploring.
We're failing to harness the extensibility
Gecko/Firefox has a complicated code lifecycle and landing process. This could be significantly streamlined if we fully harnessed and embraced the extensibility of Mercurial. While there are some Mozilla-centric extensions (details in my recent post), I don't think they are well known nor used.
I think Mozilla should embrace the functionality of extensions like these (whether they be for Mercurial, Git, or something else) and invest resources in improving the workflows for all developers. Until these tools are obviously superior and advertised, I believe many developers will unknowingly continue to toil without them. And, it's likely hurting our ability to attract and retain new contributors as well.
Conclusion
Mozilla's current usage of Mercurial is far from ideal. It's no wonder people don't like Mercurial (and why some want to switch to Git).
Fortunately, little has to do with shortcomings of Mercurial itself (at least with newer versions). If you want to know why Mercurial isn't working too well for Gecko/Firefox development, most of the problems are self-inflicted or the solutions reside within each of us. Time will tell if we as a community have the will to address these issues.
Thoughts on Mercurial (and Git)
May 12, 2013 at 12:00 PM | categories: Mozilla, Mercurial, GitMy first experience with Mercurial (Firefox development) was very unpleasant. Coming from Git, I thought Mercurial was slow and perhaps even more awkward to use than Git. I frequently encountered repository corruption that required me to reclone. I thought the concept of a patch queue was silly compared to Git branches. It was all extremely frustrating and I dare say a hinderance to my productivity. It didn't help that I was surrounded by a bunch of people who had previous experience with Git and opined about every minute difference.
Two years later and I'm on much better terms with Mercurial. I initially thought it might be Stockholm Syndrome, but after reflection I can point at specific changes and enlightenments that have reshaped my opinions.
Newer versions of Mercurial are much better
I first started using Mercurial in the 1.8 days and thought it was horrible. However, modern releases are much, much better. I've noticed a steady improvement in the quality and speed of Mercurial in the last few years.
If you aren't running 2.5 or later (Mercurial 2.6 was released earlier this month), you should take the time to upgrade today. When you upgrade, you should of course read the changelog and upgrade notes so you can make the most of the new features.
Proper configuration is key
For my workflow, the default configuration of Mercurial out of the box is... far from optimal. There are a number of basic changes that need to be made to satisfy my expectations for a version control tool.
I used to think this was a shortcoming with Mercurial: why not ship a powerful and useful environment out of the box? But, after talking to a Mercurial core contributor, this is mostly by design. Apparently a principle of the Mercurial project is that the CLI tool (hg) should be simple by default and should minimize foot guns. They view actions like rebasing and patch queues as advanced and thus don't have them enabled by default. Seasoned developers may scoff at this. But, I see where Mercurial is coming from. I only need to refer everyone to her first experience with Git as an example of what happens when you don't aim for simplicity. (I've never met a Git user who didn't think it overly complicated at first.)
Anyway, to get the most out of Mercurial, it is essential to configure it to your liking, much like you install plugins or extensions in your code editor.
Every person running Mercurial should go to http://mercurial.selenic.com/wiki/UsingExtensions and take the time to find extensions that will make your life better. You should also run hg help hgrc to view all the configuration options. There is a mountain of productivity wins waiting to be realized.
For reference, my ~/.hgrc. Worth noting are some of the built-in externsions I've enabled:
- color - Colorize terminal output. Clear UX win.
- histedit - Provides git rebase --interactive behavior.
- pager - Feed command output into a pager (like less). Clear UX win.
- progress - Draw progress bars on long-running operations. Clear UX win.
- rebase - Ability to easily rebase patches on top of other heads. This is a basic feature of patch management.
- transplant - Easily move patches between repositories, branches, etc.
If I were on Linux, I'd also use the inotify extension, which installs filesystem watchers so operations like hg status are instantaneous.
In addition to the built-in extensions, there are a number of 3rd party extensions that improve my Mozilla workflow:
- mqext - Automatically commit to your patch queue when you qref, etc. This is a lifesaver. If that's not enough, it suggests reviewers for your patch, suggests a bug component, and let's you find bugs touching the files you are touching.
- trychooser - Easily push changes to Mozilla's Try infrastructure.
- qimportbz - Easily import patches from Bugzilla.
- bzexport - Easily export patches to Bugzilla.
I'm amazed more developers don't use these simple productivity wins. Could it be that people simply don't realize they are available?
Mozilla has a bug tracking easier configuration of the user's Mercurial environment. My hope is one day people simply run a single command and get a Mozilla-optimized Mercurial environment that just works. Along the same vein, if your extensions are out of date, it prompts you to update them. This is one of the benefits of a unified developer tool like mach: you can put these checks in one place and everyone can reap the benefits easily.
Mercurial is extensible
The major differentiator from almost every other version control system (especially Git) is the ease and degree to which Mercurial can be extended and contorted. If you take anything away from this post it should be that Mercurial is a flexible and agile tool.
If you want to change the behavior of a built-in command, you can write an extension that monkeypatches that command. If you want to write a new command, you can of course do that easily. You can have extensions interact with one another - all natively. You can even override the wire protocol to provide new capabilities to extend how peers communicate with one another. You can leverage this to transfer additional metadata or data types. This has nearly infinite potential. If that's not enough, it's possible to create a new branching/development primitive through just an extension alone! If you want to invent Git-style branches with Mercurial, you could do that! It may require client and server support, but it's possible.
Mercurial accomplishes this by being written (mostly) in Python (as opposed to C) and by having a clear API on which extensions can be built. Writing extensions in Python is huge. You can easily drop into the debugger to learn the API and your write-test loop is much smaller.
By contrast, most other version control systems (including Git) require you to parse output of commands (this is the UNIX piping principle). Mercurial supports this too, but the native Python API is so much more powerful. Instead of parsing output, you can just read the raw values from a Python data structure. Yes please.
Since I imagine a lot of people at Mozilla will be reading this, here are some ways Mozilla could leverage the extensibility of Mercurial:
- Command to create try pushes (it exists - see above).
- Record who pushed what when (we have this - it's called the pushlog).
- Command to land patches. If inbound1 is closed, automatically rebase on inbound2. etc. This could even be monkeypatched into hg push so pushes to inbound are automatically intercepted and magic ensues.
- Record the automation success/fail status against individual revisions and integrate with commands (e.g. only pull up to the most recent stable changeset).
- Command to create a review request for a patch or patch queue.
- Command to assist with reviews. Perhaps a reviewer wants to make minor changes. Mercurial could download and apply the patch(es), wait for your changes, then reupload to Bugzilla (or the review tool) automatically.
- Annotating commits or pushes with automation info (which jobs to run, etc).
- Find Bugzilla component for patch (it exists - see above).
- Expose custom protocol for configuring automation settings for a repository or a head. e.g. clients (with access) could reconfigure PGO scheduling, coalescing, etc without having to involve RelEng - useful for twigs and lesser used repositories.
- So much more.
Essentially, Mercurial itself could become the CLI tool code development centers around. Whether that is a good idea is up for debate. But, it can. And that says a lot about the flexibility of Mercurial.
Future potential of Mercurial
When you consider the previous three points, you arrive at a new one: Mercurial has a ton of future potential. The fact that extensions can evolve vanilla Mercurial into something that resembles Mercurial in name only is a testament to this.
When I sat down with a Mercurial core contributor, they reinforced this. To them, Mercurial is a core library with a limited set of user-facing commands forming the stable API. Since core features (like storage) are internal APIs (not public commands - like Git), this means they aren't bound to backwards compatibility and can refactor internals as needed and evolve over time without breaking the world. That is a terrific luxury.
An example of this future potential is changeset evolution. If you don't know what that is, you should because it's awesome. One of the things they figured out is how to propagate rebasing between clones!
Comparing to Git
Two years ago I would have said I would never opt to use Mercurial over Git. I cannot say that today.
I do believe Git still has the advantage over Mercurial in a few areas:
- Branch management. Mercurial branches are a non-starter for light-weigh work. Mercurial bookmarks are kinda-sorta like Git branches, but not quite. I really like aspects of Git branches. Hopefully changeset evolution will cover the remaining gaps and more.
- Patch conflict management. Git seems to do a better job of resolving patch conflicts. But, I think this is mostly due to Mercurial's patch queue extension not using the same merge code as built-in commands (this is a fixable problem).
- Developer mind share and GitHub. The GitHub ecosystem makes up for many of Git's shortcomings. Bitbucket isn't the same.
However, I believe Mercurial has the upper hand for:
- Command line friendliness. Git's command line syntax is notoriously awful and the concepts can be difficult to master.
- Extensibility. It's so easy to program custom workflows and commands with Mercurial. If you want to hack your version control system, Mercurial wins hands down. Where Mercurial embraces extensibility, I couldn't even find a page listing all the useful Git extensions!
- Open source culture. Every time I've popped into the Mercurial IRC channel I've had a good experience. I get a response quickly and without snark. Git by contrast, well, let's just say I'd rather be affiliated with the Mercurial crowd.
- Future potential. Git is a content addressable key-value store with a version control system bolted on top. Mercurial is designed to be a version control system. Furthermore, Mercurial's code base is much easier to hack on than Git's. While Git has largely maintained feature parity in the last few years, Mercurial has grown new features. I see Mercurial evolving faster than Git and in ways Git cannot.
It's worth calling out the major detractors for each.
I think Git's major weakness is its lack of extensibility and inability to evolve (at least currently). Git will need to grow a better extensibility model with better abstractions to compete with Mercurial on new features. Or, the Git community will need to be receptive to experimental features living in the core. All of this will require some major API breakage. Unfortunately, I see little evidence this will occur. I'm unable to find a vision document for the future of Git, a branch with major new features, or interesting threads on the mailing list. I tried to ask in their IRC channel and got crickets.
I think Mercurial's greatest weakness is lack of developer mindshare. Git and GitHub are where it's at. This is huge, especially for projects wanting collaboration.
Of all those points, I want to stress the extensibility and future potential of Mercurial. If hacking your tools to maximize potential and awesomeness is your game, Mercurial wins. End of debate. However, if you don't want to harness these advantages, then I think Git and Mercurial are mostly on equal footing. But given the rate of development in the Mercurial project and relative stagnation of Git (I can't name a major new Git feature in years), I wouldn't be surprised if Mercurial's feature set obviously overtakes Git's in the next year or two. Mind share will of course take longer and will likely depend on what hosting sites like GitHub and Bitbucket do (I wouldn't be surprised if GitHub rebranded as CodeHub or something some day). Time will tell.
Extending case study
I have removed the case study that appeared in the original article because as Mike Hommey observed in the comments, it wasn't a totally accurate comparison. I don't believe the case study significantly added much to the post, so I likely won't write a new one.
Conclusion
From where I started with Mercurial, I never thought I'd say this. But here it goes: I like Mercurial.
I started warming up when it became faster and more robust in recent versions in the last few years. When I learned about its flexibility and the fundamentals of the project and thus its future potential, I became a true fan.
It's easy to not like Mercurial if you are a new user coming from Git and are forced to use a new tool. But, once you take the time to properly configure it and appreciate it for what it is and what it can be, Mercurial is easy to like.
I think Mercurial and Git are both fine version control systems. I would happily use either one for a new project. If the social aspects of development (including encouraging new contributors) were important to me, I would likely select Git and GitHub. But, if I wanted something just for me or I was a large project looking for a system that scales and is flexible or was looking to the future, I'd go with Mercurial.
Mercurial is a rising star in the version control world. It's getting faster and better and enabling others to more easily innovate through powerful extensions. The future is bright for this tool.
Mozilla Automation Load Over Time
May 06, 2013 at 11:45 AM | categories: MozillaThis chart plots per-month sums of total time of jobs in Mozilla's automation in days. The line running through it is a best fit linear regression.
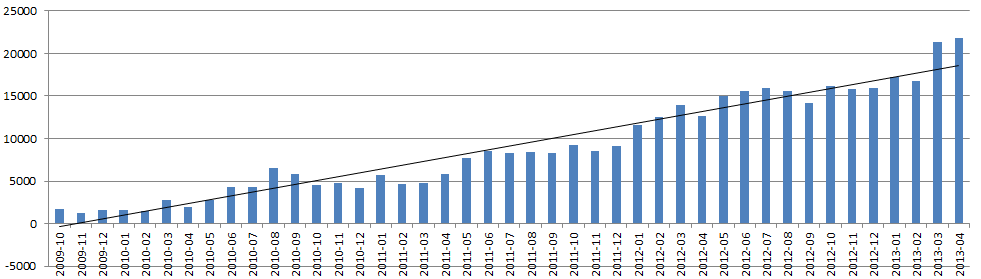{kind=link}
The raw data is available.
SQLite.jsm - SQLite Done Betterer
April 14, 2013 at 11:55 PM | categories: MozillaDid you know there is now a better way to interact with SQLite from JavaScript in Firefox? It's called SQLite.jsm and it's available in Firefox 20 and later.
SQLite.jsm is an abstraction around the low-level Storage APIs that you would have used before. However, it eliminates most of the footguns and makes it easier to write code that doesn't jank the browser and is less prone to memory leaks. It even has an API to free as much memory as possible from the current connection!
If you currently use SQLite via Storage, I highly recommend taking a look at SQLite.jsm - especially if you are using synchronous APIs.
If you are investigating SQLite for the storage needs of your add-on or browser feature, please keep in mind that SQLite can incur lots of filesystem I/O and may run slowly on old machines (especially with magnetic hard drives) and especially with its default configuration. You may be interested in low-level file I/O using OS.File instead.
If you insist on using SQLite, please educate yourself on and then seriously consider using Write-Ahead Logging mode on your database. Some detailed discussion on SQLite behavior as it pertains to Firefox can be found in bug 830492. I hope to eventually incorporate more sane by default connection options into SQLite.jsm to make it easier for add-ons and browser features to have the least-impactful behavior by default (e.g. enable WAL by default). Until then, please, please, please research PRAGMA statements to optimize how your SQLite database runs so it has as little performance overhead as possible. Also consider dropping into an IRC channel on irc.mozilla.org and asking for advice from one of the many who have fallen into SQLite's many performance pitfalls (including me).
Making hg-git Faster
April 14, 2013 at 09:45 PM | categories: Mozilla, Mercurial, GitWhen enterprising individuals at Mozilla started maintaining a Git mirror of Firefox's main source repository (hosted in Mercurial), they ran into a significant problem: conversion was slow. The initial conversion apparently took over 6 days and used a lot of memory. Furthermore, each subsequent commit took many seconds, even on modern hardware. This meant that the they could only maintain a Git mirror of a few project branches and that updates would be slow. Furthermore, the slowness of the conversion significantly discouraged people from using the tool locally as part of regular development.
I thought this was unacceptable. I wanted to enable people to use their tool of choice (Git) to develop Firefox. So, I did what annoyed engineers do when confronted with an itch: I scratched it.
Diagnosing the Problem
When I started tackling this problem, I had little knowledge of the problem space other than the problem statement: converting from Mercurial to Git is prohibitively slow and that the slow tool was hg-git. My challenge was thus to make hg-git faster.
When confronted with a performance problem, one of the first things you do is identify the source of the bad performance. Then, you need to acertain whether that is something you have the ability to change.
This often starts by answering some high-level questions then drilling down into more detail as necessary. For a long-running system tool like hg-git, I start with the top test: how much CPU, memory, and I/O is the process utilizing?
In the case of hg-git, we were CPU bound. The Python process was consistently pegging a single CPU core while periodically incurring I/O (but not nearly enough to saturate a magnetic disk). This told me a few things. First, I should look for bottlenecks inside Python. Second, I should investigate whether parallel execution would be possible. The latter is especially important these days because the trend in processors is towards more cores rather than higher clock speeds. It's no longer acceptable to let increases in clock speed or cycle efficiency bail you out: if you want a CPU bound process to run as fast as possible, it's often necessary to involve all available CPU cores.
Once I diagnosed CPU as the limiting factor, I pulled out the next tool in the arsenal: a code profiler. I quickly discovered exactly where the conversion was taking the most CPU time. As feared, it was in the export Mercurial changeset to Git commit function. Specifically, profiling had flagged the conversion of Mercurial manifests to Git trees and blobs. Furthermore, most of the time was spent in functions in Mercurial itself (Mercurial is implemented in Python and hg-git calls into it natively) and Dulwich (a pure Python implementation of Git). So, I was either looking at deficiencies or Mercurial and/or Dulwich, a bad conversion algorithm in hg-git, or both. To know which, I would need a better grasp on the internal storage models of Mercurial and Git.
Learning about Mercurial's and Git's internal storage models
To understand why conversion from Mercurial to Git was slow, I needed to understand how each stored data internally. My hope was that if attained better understanding I could apply the knowledge to assess the algorithm hg-git was using and optimize it, hopefully introducing parallel execution along the way.
Git's internals
I already had a fairly good understanding of how Git works internally. And, it's quite simple really. The Git Internals chapter of the Pro Git is extremely useful. While I encourage readers to read all of the Git Objects section, the gist is:
- Git's core storage is a key-value data store. Keys are SHA-1 checksums of content. Each entity is storage in a Git object.
- A blob is an object holding the raw content of a file.
- A tree is an object holding a list of tree entries. Each tree entry defines a blob, another tree object, etc. A tree is essentially a directory listing.
- A commit object holds metadata about an individual Git commit. Each commit object refers to a specific tree object.
When you introduce a new file that hasn't been seen before, a new blob is added to storage. That blob is referenced by a tree. When you update a file, a new tree is created referring to the new blob that was created.
Things get a little complicated when you consider directories. If you update the file foo/bar/baz.c, the tree for foo/bar changes (because the SHA-1 of baz.c changed). And, the SHA-1 for the foo/bar tree changes, so the bar entry in foo's tree changes, changing the SHA-1 for the root tree.
That's essentially how Git addresses commits, directories, and files. If you don't grok this, please, please read the aforementioned page on it - it may even help you better grok Git!
Mercurial's internals
Unlike Git, I didn't really have a clue how Mercurial worked internally. So, I needed to do some self-education here.
The best resource for Mercurial's storage model I've found is the Behind the Scenes chapter from Mercurial: The Definitive Guide. The gist is:
- History for an individual file is stored in a filelog. Each filelog contains the history of a single file. Each file revision has a hash based on the file contents.
- The manifest lists every file, its permissions, and its file revision for each changeset in the repository.
- The changelog contains information about each changeset, including the revision of the manifest to use.
- Each of these logs contain revisions and you can address an individual revision within the log.
From a high level, Mercurial's storage model is very similar to Git's. They both address files by hashing their content. Where Git uses multiple tree objects to define every file in a commit, Mercurial has a single manifest containing a flat list. Aside from that, the differences are mostly in implementation details. These are important, as we'll soon see.
Analyzing hg-git's conversion algorithm
Armed with knowledge of how Git and Mercurial internally store data, I was ready to analyze how hg-git was performing conversion from Mercurial to Git. Since profiling revealed it was the convert a single changeset into Git commit function that was taking all the time, I started there.
In Python (but not the actual Python), the algorithm was essentially:
def export_changeset_to_git(changeset, git, already_converted): """Receives the Mercurial changeset and a handle on a Git object storre.""" # This is an entity that helps us build Git tree objects from # paths and blobs. The logic is at # https://github.com/jelmer/dulwich/blob/2a8548be3b1fd4a1ae7d0436dce91611112c47c2/dulwich/index.py#L298 tree_builder = TreeBuilder() for file in changeset.manifest: blob_id = already_converted.get(file.id, None) if blob_id is None: blob = Blob(file.data()) git.store(blob.id, blob.content) already_converted[file.id] = blob.id blob_id = blob.id tree_builder.add_file(file.path, blob_id, file.mode) for tree in tree_builder.all_trees(): git.store(tree.id, tree.content) root_tree = tree_builder.root_tree # And proceed to build the Git commit and insert it.
On the face of it, this code doesn't seem too bad. If I were writing the functionality from scratch, I'd likely do something very similar. So, why is it so slow?
As I mentioned earlier, profiling results had identified Mercurial and Dulwich as the hot spots. The Mercurial hotspot was in iteration over the files in the manifest. And the Dulwich offender with Git tree object construction. By why?
First, it turns out that iterating a manifest the way hg-git was isn't exactly performant. I never traced all the gory details, but I'm pretty sure every time it accessed the file context through the change context there was I/O involved. Not good, especially if you may not need the information contained if it was already cached!
Second, it turns out that creating Git tree objects in Dulwich is rather slow. And, the problem is magnified when converting large repositories - like mozilla-central (Firefox's canonical repository).
So, I was faced with a decision: make Mercurial and/or Dulwich faster or change hg-git. Since improving these would have benefits outside of hg-git, I initially went down those roads. However, I eventually abandonded the effort because of effort involved. And, in the case of Dulwich, improving things would likely require rewriting some pieces in C - not something I cared to do nor something that the Dulwich people would likely accept since Dulwich is all about being a pure Python implementation of Git! And in hindsight, this was the right call. Mercurial and Dulwich are fast enough - it's hg-git that was being suboptimal.
I was faced with two problems: don't mass iterate over manifests and don't mass generate Git trees. Both were seemingly impossible to avoid because both are critical to converting a Mercurial changeset to Git.
I thought about this problem for a while. I experimented with numerous micro benchmarks. I engaged the very helpful Mercurial developers on IRC (thanks everyone!). And, I eventually arrived at what I think is an elegant solution.
When I took a step back and looked at the larger problem of exporting Mercurial changesets to Git, I realized it would be beneficial in terms of efficiency for the conversion to be more aware of what had occurred before. Before I came along, hg-git was asking Mercurial for the full state of each changeset for each changeset conversion. When you think about it in low-level operations, this is extremely inefficient. Let's take Git trees as an example.
When you perform a commit, only the trees - and their parents - that had modified files will change. All the other trees will be identical across commits. For large repositories (in terms of files and directories) like mozilla-central, the number of static trees across small commits is quite significant compared to changed trees. The overhead of computing all these trees is not insignificant!
Instead of throwing away all the trees and file context information between changeset exports, what if I preserved it and reused it for the next changeset? I think I'm on to something...
Implementing incremental changeset export
To minimize the work performed when exporting Mercurial changesets to Git, I implemented a standalone class that can emit Mercurial changeset deltas in terms of Git objects. Essentially, it caches a Git tree representation of a Mercurial manifest. When you feed a new Mercurial changeset into it, it asks Mercurial to compare those changesets using the same API used by hg status. This API is efficient and returns the information I care about: the paths that changed. Once we have the changed files, we simply reflect those changes in terms of updating Git trees.
If a file changes or is added, we emit a blob. If a tree changes, we emit the new tree object. When the consumer has finished writing the set of new objects to Git, it asks for the SHA-1 of the root tree. (Up until this point the consumer is not aware of what any of the emitted objects actually are - just that they likely need to be added to storage.) It then uses the SHA-1 of the root tree to construct the commit. Then it moves on to the next changeset.
The impact of this change is significant. On my computer, converting Mercurial's own Mercurial repository Git went from 21:07 to 8:14 on my i7-2600k. mozilla-central is even more drastic. The first 200 commits (the first commit was a large dump from CVS) took 8:17 before and now take 2:32. I don't have exact numbers from newer commits, but I do know they were at least twice as slow as the initial commits and showed an even more drastic speedup.
But I was just getting started.
The initial implementation wasn't very efficient in terms of reducing tree object calculations. I changed that earlier today when I submitted a patch for consideration that only calculates tree changes for trees that actually changed. I also removed some needless sorting on the order of export operations. This second patch reduced conversion of Mercurial's repository down to 5:33. Even more impressive is that mozilla-central's changesets are now exporting almost 4x faster with this patch alone. The first 200 changesets now export in 42s (down from 2:32 which is down from 8:17). This is mostly due to the overhead of reprocessing non-dirty trees on every export.
And I'm not through.
As part of building the standalone incremental changeset exporter, one of the goals in the back of my mind was to eventually have things execute in parallel.
In my personal development branch I have a patch to perform Mercurial changeset export on multiple cores. Essentially hg-git fires up a bunch of worker processes and asks each to export a consecutive range of changesets. The workers writes new Git objects into Git and then tells the coordinator process the root tree SHA-1 corresponding to each Mercurial changeset. The coordinator process then uses these root tree SHA-1's to derive Git commit objects (you can't create the commit object until you know the SHA-1 of the commit's parents).
The blob and tree exporting on separate processes makes Mercurial to Git export scale out to however many cores you feel like throwing at it. When 32 core machines come around, you can convert using all available cores and the speedup should roughly be linear with the number of cores.
I'm still working out some kinks in the multiple processes patch (the multiprocessing module is very difficult to get working on all platforms and I don't want to break hg-git when it lands). But, Ehsan Akhgari has been using it to power the GitHub mirror of mozilla-central for months without issue. (His use of these patches freed up the CPU required to support conversion of more project branches on the Git mirror. And, he's still not using the 4x improvement patch I wrote today - he will shortly - so who knows what improvements will stem from that.)
With all the patches applied, hg-git now feels like a Ferrari when exporting Mercurial changesets to Git. Conversion of Mercurial's repository now takes 1:25 (down from 21:07). Conversion of mozilla-central has gone from 6+ days to about 3 hours! More importantly, ongoing conversions feel somewhat snappy now.
Making Git export even faster
With the patch today, I'd say optimization of exporting Mercurial changesets is nearing its limits. There are a few things I could try that may net another 2 or 3x improvement. But, I think the ~50x improvement I've already attained (at least for mozilla-central) is pretty damn good and good enough for most users. (Part of performance optimization is knowing when is good enough and stopping before you invest excessive time in the long tail.)
There is one giant refactor that could likely net a significant win for Git export. However, it requires optimizing for initial export over recurring incremental export (which is why I have little interest in it). Incremental export incurs a lot of random I/O accessing Mercurial filelogs and extracting specific file revisions as they are needed. An optimal export would iterate over the filelogs and export Git blobs from each filelog in the sequence they occur in within the filelogs. It would cache the file node to blob SHA-1. After all blobs are exported, the mappings would be combined and distributed to all workers. Then, tree export would occur in parallel largely under the existing model modulo blob writing. This would minimize overall I/O and work in Mercurial and would likely be significantly faster. However, it's mostly useful for initial export and IMO not worth implementing. (It's possible to employ a variation for incremental export that iterates over filelogs and exports not-yet-seen revisions. Perhaps I will investigate this some day.)
What about converting Git to Mercurial?
Now that I've tackled Mercurial to Git conversion, it's very tempting to work magic on the inverse: converting Git commits to Mercurial changesets. While I haven't looked at this problem in detail, I already know it will be at least slightly more challenging.
The reason is parallelization. With Mercurial export, I have each child process reading directly from Mercurial and writing directly to Git. There are no locks involved. There is just a coordinator that ensures minimum redundant work among workers. There is some redundant work, sure. But, the alternative would be lots of locking and/or exchange of state across processes - not cheap operations! Furthermore, the writes into Git can occur in any order (since Git is just a key-value store). The only hard requirement is a child commit must come after its parent (because you need the parent commit's SHA-1). And, single-threaded insert of commit objects isn't a big deal because you can crank through hundreds of them per second (it might even be over 1000/s on my machine).
Mercurial's storage implementation does not afford me the same carelessness with regards to writing into storage. Since Mercurial uses shared files for individual file and manifest history, we have a contention problem. We could lock files when writing to them. However, these files (revlogs in Mercurial speak) also use transparent delta compression. You get the best performance/compression when changes are written in the order they actually occured in (at least in the typical case).
To optimally write to Mercurial you need to order inserts. This means parallel reads from Git (in separate worker processes) would be very difficult to implement. Doable, sure, but you're looking at a lot of transferred state and ordering. This likely involves a lot more memory and CPU usage.
The best idea I've come up with so far is a single process that reads off Git commits and iterates trees. It hashes the paths of seen files to a consistent worker process which then pulls the blob from Git's storage and inserts it into the filelog. You don't need to lock filelogs because only one worker owns a specific path. Workers report the blob's corresponding file node to another process which then assembles manifests, writes manifests in order, and finally creates and writes changesets. Unfortunately, the worker processes are just doing blob I/O. There is no parallel processing of Git tree calculation or Mercurial manifests. Given this was a significant source of slowness exporting to Git, I worry the inverse will be true. Although, the problem with Git was tree creation and it was due to the volume. Since there is only 1 manifest per changeset, perhaps it won't be as bad.
While I've brainstormed a solution, I have no concrete plans to work on Git to Mercurial conversion. The impetus for me working on Mercurial to Git speedups was that I and a number of other Mozilla people were personally impacted. If the same is true for Git to Mercurial slowness, I could invest a few hours the next time I'm sick and bored over the weekend.
Conclusion
Converting Mercurial repositories to Git with hg-git is now significantly faster. If you thought it was too slow before, grab the latest code (from either the official repository or my personal branch) and enjoy.
« Previous Page -- Next Page »